- Make a subdirectory in your current directory for constructing your
data type and its related files. For example, if you choose
the directory name
~/explorer/myType:
mkdir ~/explorer/myType
Go to that directory:
cd ~/explorer/myType - Put the gnBase.t file in the subdirectory.
- Make a file called
TYPES
in the same subdirectory and put the name of the data type in it. For
example,
cat > TYPES gnBase ^DThis TYPES file now contains the name gnBase.
- Create a Makefile for your ~/explorer/myType directory by running the type Makefile generator. Type the command:
cxmkmfIRIS Explorer then creates an Imakefile and a Makefile.
- Build the type and related files by typing:
make all- Install the type into the $EXPLORERUSERHOME subdirectory so that it will be visible to all of IRIS Explorer by running the command:
make install - Create a Makefile for your ~/explorer/myType directory by running the type Makefile generator. Type the command:
This command installs the made files in $EXPLORERUSERHOME. Their names and functions are described below.
What the Type Files Do
When you build a type, IRIS Explorer translates the language in the type declaration file into C and creates the .type file. It also creates a header file for the data type (.h) and an include file (.inc). You must include one of these files in the (C or Fortan) user function file when you write a module that makes use of the new type.
To be more specific, suppose that you have created the data structure for a data type called gnBase by using the principles described in "Using the ETL", above. The data structure has been saved in a file called gnBase.t. Building and installing the type creates a number of files under $EXPLORERUSERHOME. The files have these uses:
- $EXPLORERUSERHOME/include/cx/gnBase.t
- The original type definition file. Placed into a known location so that it can be included in other type files. For example, cxLattice.t is used in cxPyramid.t .
- $EXPLORERUSERHOME/include/cx/gnBase.h
- The generated C structure definition for the type. This header file must be included by C programs that manipulate the type.
- $EXPLORERUSERHOME/include/cx/gnBase.inc
- The generated Fortran definition of all enumerated constants used in building the type. This header file must be included by Fortran programs that manipulate the type.
Since the Fortran programmer must access the type through a set of subroutines and functions, the enumerated constants are necessary as function parameters. No structure information is included in the Fortran include file, since IRIS Explorer structures are not accessed directly from Fortran.
- $EXPLORERUSERHOME/include/cx/gnBase.api.h
- The C header file containing function prototypes for the application programmer interface to the type's accessor functions. See the library file gnBase.a below for a discussion of the accessor functions.
- $EXPLORERUSERHOME/include/cx/gnBase.api.inc
- The Fortran include file containing the definition of all return values from the type's accessor functions. See the library file gnBase.a below for a discussion of the accessor functions.
- $EXPLORERUSERHOME/lib/gnBase.a
- In the process of building a type, several accessor functions are created
to allocate the type, to set and get members of the type, to inquire about
the enumerated type and length of members, and to read and write data of
this type in the standard IRIS Explorer transcribed form. Both C and Fortran
versions of the library are created and stored in the archive
.a file.
In addition, the library contains an object file gnBase.meta.o, which contains a C structure describing the type. This "meta-type" description is required by the type accessor library and fully describes the type: it is a compiled object representation of the gnBase.t file.
- $EXPLORERUSERHOME/types/gnBase.type
- The gnBase.type file is a binary version of the gnBase.meta.obj structure that can be loaded by IRIS Explorer at run-time. It is used by the Map Editor and Module Builder to discover the description of types.
Figure
8-1
shows the sequence of events in the build process.
Data types are present in many guises within IRIS Explorer. You can
use the Module Builder to create a series of modules that use the new data
type, then wire the modules into a map in the Map Editor and look at the
results. You will be able to see the various manifestations of the data
type declarations. The data types are visible to users at several places in the GUI (graphical
user interface). In the Map Editor, the user sees the data type on each
module port when a map is wired. The Map Editor uses the data types and
auxiliary constraint information to determine which ports are valid for
a given wiring, hence the IO pad highlighting to illuminate potential wiring
destinations. In the Module Builder, the module writer sees a menu of all available
port data types when creating input and output ports. Input and output
ports can be of any root data type. The Module Builder must configure these
menus at run time from the wiring connections made in the Connections panel.
Description strings appear as menu items in the Connections window.
Module communication across socket links, for example between modules
on different hosts or on a single host with non-shared memory, requires
that both the sender and receiver know how to transmit the data structure.
IRIS Explorer data structures may have variably sized portions, pointers
to shared pieces, and may even be recursive. Each module is compiled with
the necessary information about its constituent data types, so that it
can correctly transmit, read, and write those types. Furthermore, some
modules, such as For and While, must
be able to receive and send data structures that were not known when they
were built. Each data type is a structure made up of several members. The structure
members can be scalars of certain types, or compositions of scalars in
the form of arrays, unions, and structures. Associated with each member
is a set of accessor functions, the application programming interface (API),
that allows the user to set and get its value. The API is automatically
generated from the label given to each member, either by the user or internally
by the typing system. Table
8-4 gives an example of a member: IRIS Explorer suppresses spaces and other non-alphanumeric characters
such as parentheses, and runs the alphanumeric characters together to form
the base name of the API routine. It then adds the type prefix (which for
IRIS Explorer is cx). For the above example, the API routines
would have the base name shortNoOfItems*. A verb (either Get
or Set) that indicates the function of the API routine is then
appended; for example, to manipulate count, you can call shortNoOfItemsGet
and shortNoOfItemsSet. All members get the functions *Get and *Set, and some
members have additional routines. These are listed in the next section,
and you can refer to the generated header file for the API (.api.h)
for the function definition. Here is a list of the types of members and their functions. In this
example, the type is called myType, the
label is Label, and a trailing name indicates the form of access.
All members of a data type get these routines: The reference-counted structures get these routines: Note: cxDataRefDec() is used to delete all reference-counted
structures. The arrays get these routines: These include arrays inside datatypes such as lattice->data->dims,
the dimensions array within the cxData structure of cxLattice. In some cases, several members within a switch
construct may be given the same label. The members must lie within a discriminated
union (a switch) and no two members can lie in the same case of the union.
In this case, the several members take on a single identity, with the active
member depending on which case of the union is active. These labelled unions have additional accessor functions: C and Fortran versions of the routines are generated and loaded into
the library files libmyType.a. All IRIS Explorer user-defined type structures are placed in shared
memory on machines with shared memory. When you use the <TYPE><LABEL>Set()
routines, they free up the memory at the location they are about to overwrite
if the member is an array. If the member being overwritten is a reference-counted
item, the reference count is decremented. Fortran wrappers are generated for almost all user-defined type API
routines. They follow the usual rules for the IRIS Explorer Fortran API:
Incorrect wrappers are generated for routines returning a
char**
return value. For example, the prototype in the
myType.api.h
file for the routine named
You can suppress generation of these routines by following these steps.
Automatic Fortran wrapper generation will be suppressed for that routine. If this
routine is required, it can be created by hand.
Note: At the moment, there are problems with the Fortran
interface for functions that set strings (variables of type char*) within
a datatype, due to the vagaries of passing strings from Fortran to C. The manual pages for the API, also automatically generated, will be
installed in
$EXPLORERUSERHOME/man/man3. For information on setting the value of
the environment variable
This directory is probably not searched by default by the
man
command, but you can add this directory to your search path by defining the
IRIS Explorer maps can be distributed across a heterogenous network
of computers. Care must be taken with maps that pass user-defined data
types between machines. The Module Control Wrapper (MCW) translates the
information from the data type into a contiguous stream of data and sends
it from one machine to the other. For the process to work, the other machine
must know how to reconstitute this data stream into a recognizable data
type. This means that the data type must be installed on the other system
as well. Here is an example of a user-defined type which is basically an IRIS
Explorer lattice with the addition of three new scalars (Minimum,
Maximum, and Empty). For each data variable, there is a description
label string. This is the data type definition. It is the ETL description of the user-defined
type "tstLattice" and resides in $EXPLORERHOME/src/MWGcode/UserTypes/types/tstLattice.t.
This code uses the user-defined data type, tstLattice. It takes
in an IRIS Explorer lattice and generates a tstLattice. Before you can
make this module you must have installed the user-defined data type tstLattice,
following the instructions given in "Building the
Type and Related Files". The easiest way to demonstrate this is to connect GenLat to the
input. You can extract some information from the new data type by building
the second test module, and connecting it to the first one. The code resides
in $EXPLORERHOME/src/MWGcode/UserTypes/C/generate.c
and $EXPLORERHOME/src/MWGcode/UserTypes/Fortran/generate.f.
Resources files may be found in the same directories. This module reads in a tstLattice user-defined type and prints
out some specific information from it. The code resides in $EXPLORERHOME/src/MWGcode/UserTypes/C/print.c.
A resources file may also be found in this directory. As the Fortran wrapper
to the C function tstDataDataLabelsGet is incorrect (this function
returns a char**), the equivalent Fortran example would require
a user-generated Fortran wrapper. The Fortran example program is therefore
not supplied. There are two more modules in the directory $EXPLORERHOME/src/MWGcode/UserTypes/C,
ReadtstLattice and WritetstLattice,
that allow the user to read and write ASCII or binary versions of the user-defined
type. The user function for these modules is a simple interface to the
two auto-generated routines tstLatticeWrite and tstLatticeRead.
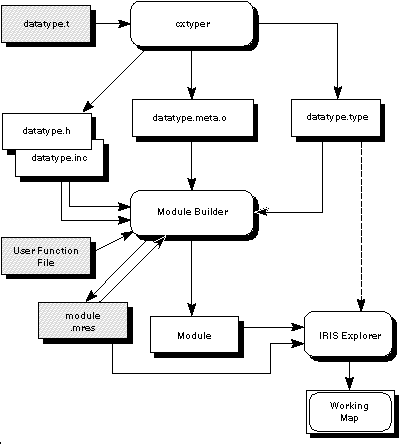
Figure 8-1 IRIS Explorer Types Information Flow
Visibility of Data Types in IRIS Explorer
In the GUI
Between Modules
Application Programming Interface
Type
Variable Name
Label
short
count
"No. Of Items"
API Member Types and Functions
Functions for All Members
Functions for Reference-counted Structures
Functions for Arrays
Dimensioning Arrays
Functions for Members in a Switch
Memory Handling
Fortran Wrappers
Suppressing char** Routines
char **myTypeItemGet( myType* src, cxErrorCode *ec );
echo "CXC2FPREPROC = c2fpreproc.sed" > Imakefile.default
cp $(EXPLORERHOME)/lib/c2fpreproc.sed c2fpreproc.sed
s/.*myTypeItemGet.*$//g
Location of API man Pages
setenv MANPATH (${MANPATH}:$EXPLORERUSERHOME/man)
Crossing Machine Boundaries
Example of a User-defined Type
#include <cx/DataCtlr.h>
#include <cx/Typedefs.t>
#include <cx/cxLattice.t>
shared root typedef struct {
long nDim "Num Dimensions";
long dims[nDim] "Dimensions Array";
tstData(nDim, dims) data "Data Structure";
cxCoord(nDim, dims) coord "Coord Structure";
} tstLattice;
shared typedef struct { /* IRIS Explorer Lattice's Data array */
long nDim;
long dims[nDim];
float minimum "Minimum";
float maximum "Maximum";
float empty "Empty";
long nDataVar "Num Data Variables";
string labels[nDataVar] "Data Labels";
cxPrimType primType "Primitive Data Type";
switch (primType) {
case cx_prim_byte:
char values[nDataVar, dims] "Data Array";
case cx_prim_short:
short values[nDataVar, dims] "Data Array";
case cx_prim_long:
long values[nDataVar, dims] "Data Array";
case cx_prim_float:
float values[nDataVar, dims] "Data Array";
case cx_prim_double:
double values[nDataVar, dims] "Data Array";
} d;
} tstData(nDim, dims);
The GentstLattice module
C Version:
/* This test module inputs a cxLattice and outputs a tstLattice.
* The differences are that the tstLattice has additional fields in the
* tstData (equivalent to cxData) structure for minimum, maximum,
* empty_cell_value, and labels for each data variable.
* This can be seen as a super-lattice.
*/
#include <cx/DataAccess.h>
#include <cx/DataTypes.h>
#include <cx/DataOps.h>
#include <cx/tstLattice.api.h>
#define CLEAN(A,B,C) if(memclean((void *)A,B,C)) return
int memclean(void *ptr, cxErrorCode ier, tstLattice *lat)
{
if((ptr == NULL) || (ier != cx_err_none))
{
cxDataRefDec(lat);
return 1;
}
else
return 0;
}
void generate(cxLattice *inLat, tstLattice **outLat)
{
char **labels;
cxCoord *coord;
cxCoordType coordType;
cxData *data;
cxErrorCode err;
cxPrimType primType;
int i, num_bytes;
long nDim,*dims,hasData,nDataVar,hasCoord,nCoordVar;
tstData *tdata;
void *inDataArray, *outDataArray;
/* Get the lattice description for the incoming lattice */
cxLatDescGet(inLat,&nDim,&dims,&hasData,&nDataVar,&primTyp
&hasCoord,&nCoordVar,&coordType);
/* Make the complete tstLattice structure and all its components
* using the incoming lattice characteristics
* Return if any of the allocations fail
*/
*outLat = tstLatticeAlloc(nDim,dims);
if(*outLat == NULL)
return;
tdata = tstDataAlloc(nDim,dims,nDataVar,primType);
CLEAN(tdata,0,*outLat);
tstLatticeDataStructureSet(*outLat,tdata,&err);
CLEAN(tdata,err,*outLat);
outDataArray = tstDataDataArrayAlloc(tdata);
CLEAN(outDataArray,0,*outLat);
tstDataDataArraySet(tdata,&outDataArray,&err);
CLEAN(tdata,err,*outLat);
cxLatPtrGet(inLat,&data,&inDataArray,&coord,NULL);
tstLatticeCoordStructureSet(*outLat,coord,&err);
CLEAN(tdata,err,*outLat);
/* Additional characteristics for the new tstLattice
* limit the data range that is accepted by the lattice
*/
tstDataMinimumSet(tdata,0.0,&err);
CLEAN(tdata,err,*outLat);
tstDataMaximumSet(tdata,1.0,&err);
CLEAN(tdata,err,*outLat);
tstDataEmptySet(tdata,-999.,&err);
CLEAN(tdata,err,*outLat);
/* Get the pointer to the labels structure and
* define the labels (they are the main difference between the
* new tstLattice type and cxLattice)
*/
labels = tstDataDataLabelsGet(tdata, &err);
CLEAN(tdata,err,*outLat);
for(i=0;i<nDataVar;i++)
{
labels[i] = cxDataMalloc(sizeof("label 99")+1);
CLEAN(labels[i],err,*outLat);
sprintf(labels[i],"label %d",i);
}
/* Copy the rest of the incoming lattice to the outgoing tstLattice */
num_bytes = cxDataPrimSize(data);
num_bytes *= cxDimsProd(nDim,dims,nDataVar);
bcopy(inDataArray,outDataArray,num_bytes);
}
Fortran Version:
SUBROUTINE GENER(INLAT,OUTLAT)
C
C fortran example for UDT's
C
INCLUDE '/usr/explorer/include/cx/DataAccess.inc'
INCLUDE '/usr/explorer/include/cx/DataOps.inc'
INCLUDE '/usr/explorer/include/cx/tstLattice.api.inc'
C
C .. Parameters ..
REAL ZERO, ONE, EMPTY
PARAMETER (ZERO=0.0,ONE=1.0,EMPTY=-999.0)
INTEGER LSIZE, MAXCHR
PARAMETER (LSIZE=4,MAXCHR=10)
C .. Scalar Arguments ..
INTEGER INLAT, OUTLAT
C .. Local Scalars ..
INTEGER COORD, CTYPE, DATA, ERR, HASCRD, HASDAT, I, IER,
* NBYTES, NCVAR, NDIM, NDVAR, P0, PTYPE, TDATA
C .. Local Arrays ..
INTEGER DIMS(1)
CHARACTER INARR(1), OUTARR(1)
CHARACTER*(MAXCHR) LABELS(1)
C .. External Functions ..
INTEGER MEMCLN
EXTERNAL CXDATAMALLOC, CXDATAPRIMSIZE, CXDIMSPROD, MEMCLN,
* TSTDATAALLOC, TSTDATADATAARRAYALLOC,
* TSTDATADATALABELSGET, TSTLATTICEALLOC
C .. External Subroutines ..
EXTERNAL CXLATDESCGET, CXLATPTRGET, TSTDATADATAARRAYSET,
* TSTDATAEMPTYSET, TSTDATAMAXIMUMSET,
* TSTDATAMINIMUMSET, TSTLATTICECOORDSTRUCTURESET,
* TSTLATTICEDATASTRUCTURESET
C .. Pointers to Lattice Structures ..
POINTER (PDIMS,DIMS)
POINTER (PIN, INARR)
POINTER (POUT, OUTARR)
POINTER (PLAB, LABELS)
C .. Executable Statements ..
C
C Get the lattice description for the incoming lattice
C
IER = CXLATDESCGET(INLAT,NDIM,PDIMS,HASDAT,NDVAR,PTYPE,HASCRD,
* NCVAR,CTYPE)
C
C Make the complete tstLattice structure and all its components
C using the incoming lattice characteristics
C Return if any of the allocations fail
C
OUTLAT = TSTLATTICEALLOC(NDIM,DIMS)
IF (OUTLAT.EQ.0) RETURN
TDATA = TSTDATAALLOC(NDIM,DIMS,NDVAR,PTYPE)
IF (MEMCLN(TDATA,0,OUTLAT).GT.0) RETURN
CALL TSTLATTICEDATASTRUCTURESET(OUTLAT,TDATA,ERR)
IF (MEMCLN(TDATA,ERR,OUTLAT).GT.0) RETURN
POUT = TSTDATADATAARRAYALLOC(TDATA)
IF (MEMCLN(POUT,0,OUTLAT).GT.0) RETURN
CALL TSTDATADATAARRAYSET(TDATA,POUT,ERR)
IF (MEMCLN(TDATA,ERR,OUTLAT).GT.0) RETURN
P0 = 0
IER = CXLATPTRGET(INLAT,DATA,PIN,COORD,P0)
CALL TSTLATTICECOORDSTRUCTURESET(OUTLAT,COORD,ERR)
IF (MEMCLN(TDATA,ERR,OUTLAT).GT.0) RETURN
CALL TSTDATAMINIMUMSET(TDATA,ZERO,ERR)
IF (MEMCLN(TDATA,ERR,OUTLAT).GT.0) RETURN
CALL TSTDATAMAXIMUMSET(TDATA,ONE,ERR)
IF (MEMCLN(TDATA,ERR,OUTLAT).GT.0) RETURN
CALL TSTDATAEMPTYSET(TDATA,EMPTY,ERR)
IF (MEMCLN(TDATA,ERR,OUTLAT).GT.0) RETURN
C
C We cannot use the Fortran API function TSTDATADATALABELSGET
C So will allocate our own array and replace it in the structure
C Free the LABELS array, after it has been copied into TDATA
C
PLAB = CXDATACALLOC(NDVAR,MAXCHR)
IF (MEMCLN(PLAB,ERR,OUTLAT).GT.0) RETURN
DO 20 I = 1, NDVAR
WRITE (LABELS(I),FMT='(''Label '',I2)') I-1
20 CONTINUE
CALL TSTDATADATALABELSSET(TDATA,LABELS,ERR)
IF (MEMCLN(TDATA,ERR,OUTLAT).GT.0) RETURN
CALL CXDATAFREE(PLAB)
C
C Copy the rest of the lattice into the tstLattice
C
NBYTES = CXDATAPRIMSIZE(DATA)*CXDIMSPROD(NDIM,DIMS,NDVAR)
DO 40 I = 1, NBYTES
OUTARR(I) = INARR(I)
40 CONTINUE
C
RETURN
END
INTEGER FUNCTION MEMCLN(PTR,ERCODE,TSTLAT)
C
C cleanup routine
C
C .. Scalar Arguments ..
INTEGER ERCODE, PTR, TSTLAT
C .. External Subroutines ..
EXTERNAL CXDATAREFDEC
C .. Executable Statements ..
C
IF ((PTR.EQ.0) .OR. (ERCODE.NE.0)) THEN
CALL CXDATAREFDEC(TSTLAT)
MEMCLN = 1
ELSE
MEMCLN = 0
END IF
RETURN
END
The PrinttstLattice module
#include <cx/DataAccess.h>
#include <cx/DataTypes.h>
#include <cx/tstLattice.api.h>
void prt( tstLattice *inlat )
{
char **f;
tstData *outData;
long i, nDV;
float mt;
cxErrorCode err;
outData = tstLatticeDataStructureGet(inlat,&err);
f = tstDataDataLabelsGet(outData,&err);
nDV = tstDataNumDataVariablesGet(outData,&err);
for(i=0;i<nDV;i++)
{
printf("label %d = %s\n",i,f[i]);
}
mt = tstDataEmptyGet(outData,&err);
printf(" Empty value = %f\n",mt);
}
Reading and Writing the User-defined Type
Last modified: Thu Jun 5 11:19:24 1997
[ Documentation Home ]