ISG+IRT/JIM is one of the first components of Infosphere software that demonstrates the usefulness of the Infopipe abstraction. Main target to be demonstrated is Infopipe Stub Generator (ISG). Infopipe Runtime System (IRT) is also designed and implemented to support ISG minimally for the Jabber Instant Messaging (JIM) system [18] with which the first infopipe application works. (The infopipe application for JIM will be described later.)
In this version of the Infopipe system, we assume that XML [10] is used to represent information which is handled by the infopipes. This means that ISG consists of code and stub generators that support the development of information flow intensive applications based on XML. The main function of ISG is to generate appropriate code for the input and output ends, so the application programmers may concentrate on the development of the processing middle. At the input end, ISG generates code to parse the incoming information flow, which in is represented in XML. At the output end, the ISG generates code to produce outgoing XML data.
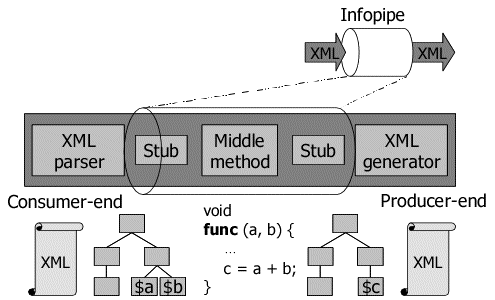
Figure 4 illustrates the overview of the Infopipe system from the viewpoint of information processing flow. We locate an XML parser at the consumer-end of the infopipe to capture information flow. It is designed to parse XML and create an internal data structure for the infopipe stub. Meanwhile, we locate an XML generator at the producer-end of the infopipe to generate outgoing information flow from the internal data structure. Here, the infopipe stub passes a part of the internal data structure to program variables for access and manipulation by the infopipe processing middle, written by the infopipe developers. Similarly, the stub passes the result of processing middle to the data structure, from which appropriate XML representation is created by the XML generator.
Figure 4: Infopipe Design from the Viewpoint of Information Processing Flow
Currently, the ISG uses DOM [11] as an internal data structure and each useful node of DOM tree is associated to a Middle program variable (*1). This binding is based on an explicit description of the Infopipe-spec. The result is that the infopipe developers can simply write the Middle code that transforms the information flow, without having to worry about the bureaucratic handling of input and output of information flow.
ISG is designed to generate also the code that invokes the middle methods as a part of stub. The timing of the method invocation is specified as the infopipe encounters a certain condition, e.g., an attribute of A element has a value "1". This means that a variety of functions, such as filters and event handlers, can be implemented in infopipes.
Figure 5 illustrates the hierarchical overview of the infopipe and its execution support architecture. The middle method execution is supported by its stub; the interface between the middle method and the stub is defined by the Infopipe-spec, which is specified by the infopipe developer. The infopipe including the stub is then supported to execute by the IRT. The interface between the infopipe stub and the IRT is defined by the Infopipe system as the Infopipe Runtime System Interface. The yellow allow in the Figure 5 shows the information processing flow.
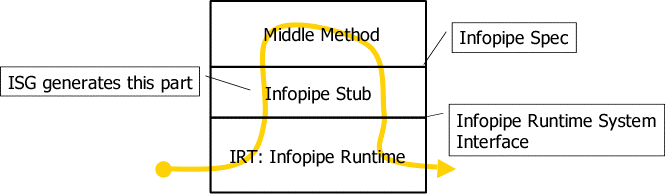
Figure 5: Infopipe and its Execution Design from the Hierarchical Point of View
The following sections describe more details of each component, which is illustrated in Figure 5, from the bottom, as well as the infopipes development flow using ISG and IRT.
Infopipe Runtime System (IRT) consists of the systems code and libraries that work with the infopipe stub. In this particular design, it contains XML processors and network protocol stack.
Regarding the XML processors, the IRT is designed to use an XML parser that creates DOM tree, which parser is invoked by the stub. The IRT is designed to use also another XML parser that should be SAX [12] base and XPath [13] processor. The SAX-base XML parser is used in the IRT itself to pass a part of XML streams to the infopipe stub that creates a DOM tree for that part. The XPath processor is used by the stub to bind a part of information and program variables. (Use of XPath is described in the following subsection, "Infopipe Spec.")
Regarding the network protocol stack, the IRT use socket and the stream data over the socket is passed to the SAX-base XML parser, and the result is written in XML representation onto the socket.
The IRT is also designed to have the adaptive interface to work with a variety of stubs; with the interface, the code for a stub is instantiated at the infopipe booting time dynamically. It enables the Infopipe developers to concentrate on writing only the Infopipe-spec and his code for the middle method.
The major two functions of the Infopipe Stub are to
The code for both functions is generated by the ISG according to the Infopipe Stub, which is specified by the infopipe developers.
Infopipe Stub works on top of the IRT, by which the Infopipe Stub is invoked through the Infopipe Runtime System Interface. (It is also called Infopipe Stub APIs from the other viewpoint.) The interface is defined by the following three APIs:
Prologue and Epilogue are issues only once at each initialization and finalization stage of the Infopipe execution. On the other side, Call may be issued twice or more whenever a part of the incoming XML document is ready to be parsed to create a DOM tree for that part.
In the Infopipe abstraction proposed by the Infosphere project, the infopipe specification is supposed to include the explicit description of both the syntax and the semantics requirements of the information flow; however, the Infopipe Spec in the system is designed to include only the syntactic description. This requires the infopipe developers to translate the semantic requirements into syntactic requirements. As far as we know through from the experiments, it is still useful.
In order to bind a part of information with program variables in the Infopipe Spec, XPath is used to address a part of XML documents (*2). Like the use of XPath in XSLT [14], key match is used to identify the condition for method invocation; when the condition which is represented in XPath is encountered, the middle method is invoked. From the location of the path as an axis, another XPath expression is used to bind a part of XML documents and a program variable.
There are two ways to specify an Infopipe Spec at present, one is to use XML and the other is to use ISL, which stands for Infopipe Specification Language.
Here is a short example of Infopipe Spec in XML.
<?xml version="1.0"?>
<!DOCTYPE InfopipeSpec SYSTEM "InfopipeSpec.dtd">
<InfopipeSpec id="InfopipeName">
<Method id="methodName" match="tagOfElement">
<InoutArgs id="argumentStructreName">
<Arg type="text" id="argumentName">tagOfChildElement/text()</Arg>
</InoutArgs>
</Method>
</InfopipeSpec>
The first line is the typical header of XML documents. The second line shows that a DTD, InfopipeSpec.dtd, is defined for the Infopipe Spec specified in XML.
In the above example, bold shows important tags
which are defined in the DTD. An attribute id of the
element InfopipeSpec defines the name of the infopipe. An
attribute id of the element Method defines
the name of the middle method; just one method or more than one
methods can be defined in the Infopipe Spec. An attribute
id of the element InoutArgs defines the name
of the argument structure for Inout in this case. (The meaning of
Inout is described later.) The element Arg may have two
attributes, one is type and the other is id;
type defines type of the program variable and
id defines the name of program variable.
Two of red in the
above example are the place where XPath representation appears, one is
for the condition of method invocation, and the other is a path to
bind the part of XML with the program variable.
At present, this XML notation is mainly used for the evaluation of the ISG+IRT/JIM system.
Infopipe Specification Language (ISL) is designed to provide a better way for infopipe developers to specify the requirements of the information flow than use XML; it can be produced either directly by the programmers, or perhaps through GUI. It is, however, natural to provide such a domain specific language for the particular purpose, although this style is not a hard requirement in the system.
ISL is intended to be more readable than use of XML for Infopipe Spec description; meanwhile, the extensibility that is realized in XML is supposed to be kept in ISL. Therefore, the current version of the ISL grammar is designed to map ISL representation onto one in XML.
Here is the short example of Infopipe Spec in ISL.
InfopipeSpec [name="InfopipeName"] {
Method [name="methodName", match="tagOfElement"] {
InoutArgs [name="argumentsStructureName"] {
Arg [type="text", name="argumentName"] {tagOfChildElement/text();}}}}
The Infopipe middle method receives the data of the consumed XML documents at its arguments as program variables. Here, three types of argument structures, In, Inout and Out, are supported. Their semantics is the same as one for the COLBA IDL as follows:
In the argument structures, infopipe developers can put some arguments, whose type should be either String text or a part of DOM tree.
Although ISG and IRT can be designed as a language independent system components, the current version of the system is designed to use Java as the target programming language; in which the infopipe developers to write their middle method of their infopipes. This reason is pretty simple: Java is appropriate for rapid prototyping especially for the first implementation as well as availability of a variety of libraries, such as XML processors.
Here is the Infopipe Development Flow using ISG and IRT. First of all, the infopipe developers need to specify their Infopipe Spec.
Second, use ISG to generate three Java files from the Infopipe Spec. The developers will get <Infopipe>.java, <Infopipe>Exception.java and <Infopipe>Stub.java. The former two Java files are used as templates and the last one, <Infopipe>Stub.java is the Stub implementation; it is not supposed to be edited by the developers.
Third, the infopipe developers need to edit and write their code for the middle method in <Infopipe>.java. If necessary, they write the exception code in <Infopipe>Exception.java, too.
Fourth, the Java compiler, javac, is used to compile the java files to class files for each. Those four steps are the all things the infopipe developers need to do before they execute the infopipe.
In order to execute the infopipe, IRT needs to be executed with the name of the Infopipe as an argument; with the name, IRT recognizes the three Infopipe class files and instantiates the stub and middle method dynamically at the booting time.
It is quite easy to build the infopipe from the Infopipe Spec.
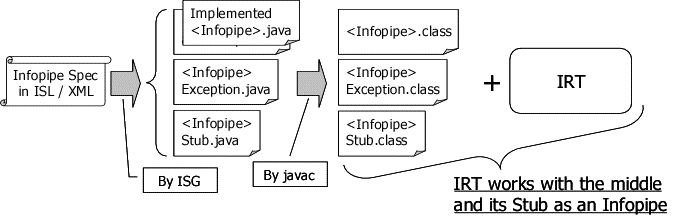
Figure 6: Infopipes Development Flow using ISG and IRT
(*1) There are two popular ways to handle XML documents, one is DOM, which is tree-based processing, and the other is SAX, which is event-based processing. DOM is appropriate for manipulating XML documents on memory; on the other hand, SAX is appropriate for processing XML as streams. SAX is also suitable for embedded systems, since its memory resource requirement is smaller than DOM. Although ISG+IRT/JIM uses DOM for the internal data structure, it uses also SAX at IRT for JIM.
(*2) Here is a small example how an XPath representation addresses a part of an XML document. We assume that there is the following XML document.
<A> <B><C>c1</C></B> <B><C>c2</C><D>d1</D></B> </A>
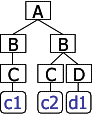
Figure 6: An Example of DOM tree and XPath
In order to address the leaf c2, one possible representation in XPath is as follow:
c2 = /A/B[2]/text()