Research
This is supposed to be a Research Overview page but it was so out of date I have removed much of the page contents for now. A moderately up to date list of my publications is here but a more complete list is best found via my Google author profile.
Below are some current/former projects at the time I left for Washington Univeristy in St. Louis:
Human Action Understanding for Human-Robot Collaboration
This work is really a shift of my activity recognition work
into the domain of robotics. In much of computer vision, activity
recognition is generating a label: this video is an example of someone
playing basketball. For a robot to react and interact, it needs to
understand the action and be able to make predictions about human
behavior. For example work see:

Hawkins, K., N. Vo, S.
Bansal, and A.F. Bobick, “Probabilistic Human Action Prediction and
Wait-Sensitive Planning for Responsive Human-Robot Collaboration,”
IEEE-RAS International Conference
on Humanoid Robots (Humanoids), 2013
Affordance learning
The set of possible actions and their outcomes with respect to the
robot and an object are referred to as affordances:
the “action possibilities” latent in the environment for a given agent.
For example, a book with a
planar side affords the ability to push it and a handle attached to a
coffee cup affords the ability to grasp it.
Traditionally, much work in robot planning presumes that the physics of
the world and its objects can be
modeled, learned and simulated in sufficient detail such that the effect
of an action in any context can be
robustly predicted. Under these assumptions the affordances of any
object can be predicted through simulation.
However, it is currently an open question as to what extent this is
possible. Even if possible, it will
certainly require extensive and exquisite sensing.

The notion of affordance based learning and action is that as
an alternative to the physics-complete planning system, a perception
driven, affordance-behavior approach allows for combining limited,
perceptually-derived geometrical information with experientially-learned
knowledge about the behavior of objects. The idea is that at any given
point in time, the robot knows about some set of objects and
experimental manipulations of those objects
whose outcomes have been recorded. Given some specific object and a task
objective, the robot will determine
a plan of actions to perform based upon already learned affordances of
similar objects.
For example work see:
Tucker Hermans, Fuxin Li, James M. Rehg, Aaron F. Bobick. "Learning Contact Locations for Pushing and Orienting Unknown Objects." IEEE-RAS International Conference on Humanoid Robotics (Humanoids), Atlanta, GA, USA, October 2013.
Tucker Hermans, Fuxin Li, James M. Rehg, Aaron F. Bobick. "Learning Stable Pushing Locations." IEEE International Conference on Development and Learning and Epigenetic Robotics (ICDL-EPIROB), Osaka, Japan, August 2013.
Human Activity Recognition 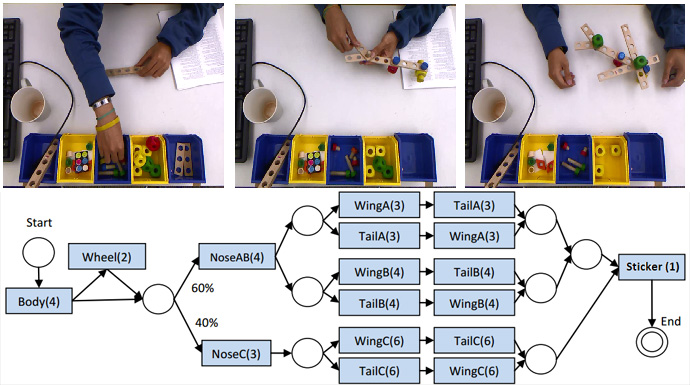
I still have an interest in activity recognition, but much less from a notion of labeling. Instead in terms of how it can be used to parse structured video. For a recent example see:
Nam Vo and Aaron Bobick, "From Stochastic Grammar to Bayes Network: Probabilistic Parsing of Complex Activity" IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014.