Before the system can support error recovery in any way, or the user can handle an error, one or the other needs to know that an error has occurred. The user interface is a conduit through which the system and user can pass information. User input can notify the system of an error (and correct it, described in more detail in the next section). And it is through visual or oral feedback that the system helps the user to identify errors.
The system can also try to determine when it has made a mistake without the user's help, either through thresholding (Baber & Hone, 1993; Poon et al., 1995; Brennan and Hulteen, 1995), a rule base (Baber & Hone, 1993; Davis, 1979), or historical statistics (Marx and Schmandt, 1994).
In the most common approaches to notification, the user explicitly
indicates the presence of an error by, for example, clicking on a
word, or saying a special keyword. Many speech and handwriting
recognition systems use this approach. Three well known examples are
the PalmPilot ![]() , DragonDictate
, DragonDictate ![]() , and the Apple
MessagePad
, and the Apple
MessagePad ![]() . For example, when the user clicks on a word in the
Apple MessagePad
. For example, when the user clicks on a word in the
Apple MessagePad ![]() , a menu of alternative interpretations
appears.
, a menu of alternative interpretations
appears.
In cases where there is no special interface for notification or correction, user action may still help the system to discover errors. For example, if the user deletes a word and enters a new one, the system may infer that an error has occurred by matching the deleted word to the new one.
There is a plethora of hidden information available to the system designer which can help users to identify errors. The likelihood that something is correct, the history of values an item has had, other possible values it could have, and the user's original input are just a few of the non application-specific ones. Our survey shows that designer after designer has found it beneficial to reveal some of this hidden information to the user (Brennan & Hulteen, 1995; Davis, 1979; Goldberg & Goodisman, 1991; Igarashi, et al., 1997 ; Kurtenbach et al., 1994; Rhodes & Starner, 1996) Two of the most common pieces of information to display are the probability of correctness (called certainty in this paper), and multiple alternatives.
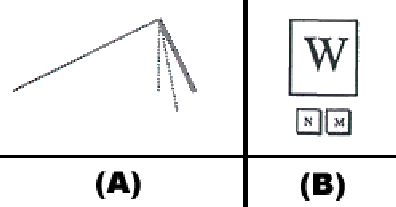
Figure 2: Pictures of two user interfaces, adapted from a paper about
drawing understanding (A, left) (Goldberg & Goodisman, 1991), and
pen input (B, right) (Igarashi et al, 1997)
An example of a system which shows information about certainty is the PenPad system. The probability of correctness is displayed through color. For example, the typewritten word PenPad is lighter (less certain) than the corresponding words ink, and in Figure 1. Figure 2 shows two example systems which display multiple alternatives. The first (Figure 2A) is a drawing understanding system designed by Igarashi et al. (1997). The bold line represents the system's current top guess. The dotted lines represent potential alternatives, and the plain line is a past accepted guess. Figure 2B shows a character recognition system designed by Goldberg & Goodisman (1991). The larger character is the system's top choice; the two smaller letters are the second and third most likely possibilities. In both systems, the user can click on an alternative to tell the system that its default choice should be changed. In both systems, if the user continues input as normal, they are implicitly accepting the default choice. Interestingly, although Igarashi had success with this approach in his drawing-understanding system, Goldberg and Goodisman found that it required too great a cognitive overhead to be effective in their character recognition system.
Both certainty and the display of multiple alternatives can also be achieved in an audio-only setting, as demonstrated by Brennan & Hulteen (1995). They base their approach on linguistic research showing that humans reveal positive and negative evidence as they converse. Positive evidence is output which confirms that the listener has heard the speaker correctly. For example, the listener may spell back a name which has just been dictated to them. Negative evidence is output which somehow reveals that the listener (in this case, the recognition system) is not sure they have understood the speaker correctly. Examples are repeating the speaker's sentence and replacing the questionable word with a pause or simply saying ``Huh?'' Negative evidence can also be used to display multiple alternatives, So, for example, the system may say ``call John or Jane?'' in response to a user's request. Brennan and Hulteen built a sophisticated response system using both techniques. They make use of positive and negative evidence, and they limit the display of alternatives based on a contextual analysis of the likelihood of correctness.
Another setting in which multiple alternatives are commonly displayed is word prediction (Alm et al., 1992; Greenberg et al., 1995). Word prediction is often used to support communication and productivity for people with disabilities which make typing, and in some cases even using a mouse, very difficult. As the user types each letter, the system retrieves a list of words which are the most likely completions of what has been typed so far. Often there are a large number of potential completions, and many are displayed at some distance from the actual input on screen.
Many error prone systems return some measure of the probability that each result is correct when they return the result. This probability represents the confidence of the interpretation. The resultant probabilities can be compared to a threshold. When they fall below the threshold, the system assumes an error has occurred. When they fall above it, the assumption is that no error has occurred. Most systems set this threshold to zero, meaning they never assume that there has been a mistake. Some systems may set it to one, meaning they always assume they are wrong (e.g., word prediction), and other systems try to determine a reasonable threshold based on statistics or other means (Poon et al., 1995; Brennan & Hulteen, 1995; Baber & Hone, 1993].
Baber & Hone (1993) suggest using a rule base to determine
when errors may have occurred.This can prove to
be more sophisticated than either statistics or thresholding since it
allows the use of context in determining whether an error has
occurred. An example rule might be:
When the user has just written
`for (', lower the probability of correctness for any alternatives to
the next word they write which are not members of the set of variable
names currently in scope.
This goes beyond simple statistics because
it uses knowledge about the context in which a word has been written
to detect errors.
When error prone systems do not return a measure of probability, or
when the estimates of probability may be wrong, new probabilities can
be generated by doing a statistical analysis of historical data about
when and where the system makes mistakes. This talk itself benefits
from good error discovery. A historical analysis can help to increase
the accuracy of both thresholding and rules.
For example, Marx & Schmandt (1994) compiled speech data about
which letters were misrecognized as ``e'', with what
frequencies, and used them as a list of potential alternatives
whenever the speech recognizer returned ``e''. They did the same
for each letter of the alphabet.
The example below shows pen data for ``e'' generated by the
first author by repeating each letter of the alphabet 25 times in a
PalmPilot ![]() . The first column represents the letter that was
written; the other columns show which letters the PalmPilot
. The first column represents the letter that was
written; the other columns show which letters the PalmPilot ![]() Graffiti
Graffiti ![]() recognizer returned. Only letters which were
mistaken for ``e'' are shown.
recognizer returned. Only letters which were
mistaken for ``e'' are shown.
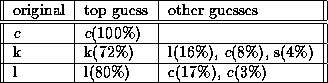
This sort of matrix is called a confusion matrix because it shows potential correct answers that the system may have confused with its returned answer. In this way, historical statistics may provide a default probability of correctness for a given answer. More sophisticated analyses can help in the creation of better rules or the choice of when to apply certain rules.
Although error discovery is a necessary component of error handling interfaces, it has a stigma associated with it: The task of error discovery is itself error prone. Rules, thresholding, and historical statistics may all be wrong. Even when the user's explicit actions are observed, the system may incorrectly infer that an error has occurred. Only when the user's action is to explicitly notify the system of an error can we be sure that an error really has occurred in the user's eyes. In other words, all of the approaches mentioned may create a new source of errors, leading to a cascade of error handling issues.