CS 2360 Lecture 15: February 2
Garbage Collection
A great deal of this material is stolen from the paper Uniprocessor
Garbage Collection Techniques by Paul R. Wilson. This appeared in the
International Workshop On Memory Management, St. Malo France,
Septemeber 1992. This paper can be retrieved by clicking here. If
you click here it
will take you to a directory with lots of neat garbage collection
stuff (including the paper above).
This lecture about automatic storage reclaimation. You are all
familiar with NEW and DISPOSE in Pascal,
and many of you are probably familiar with malloc and
free in C and/or ::new and
::delete in C++. All of these are manual (a.k.a.
explicit) storageallocation/deallocation strategies. Lisp uses a
garbage collector to automate the process of finding heap
memory that is no longer in use and reclaiming it.
(Click here to go to the
directory for the C++ garbage collector from PARC. )
Throughout this discussion we will be using two terms:
- Collector This is the part of the program that implements
the automatic reclaimation. Short for "garbage collector."
- Memory Object This is just a bunch of contiguous storage
which has been allocated on the heap. It doesn't have to be an object
in the object-oriented sense. It might be an integer, a C structure, a
Pascal record, a Smalltalk object, etc.
The basic idea of garbage collection is reclaim heap storage
automatically. When heap space is "reclaimed" it may be reused by the
running program. The collector's function is to find data objects that
are no longer in use and make their space available for
new allocations. An object is considered garbage and subject
to reclaimation when:
it is not reachable by the running program any path of pointer
traversals.
An object is considered "live" when it is reachable by some
path of pointer traversals; these objects must be preserved by the
collector. If not, the program will traverse a "dangling pointer"
(pointer to a deallocated object) and end up with a serious
problem...
Motivation
Garbage collection is a big win for "modular programming" in that
avoids needless inter-module dependencies. If you have ever programmed
in 'C' and had the "who owns the memory?" problem you'll understand
this. If you haven't had this experience yet, consider a big
application with multiple programmers operating on the same data
structures. Without a garbage collector, programmers must be
extremely careful to not reclaim objects on which other parts of the
program depend before they are done with them. Another way of thinking
of this is to consider an explicit deallocation scheme: Some part of
the program must be responsible for determining when all other
parts of the program are "done with" the data structure. This would
seem to require a breakdown in abstraction barriers...
Well, in many cases people just ignore the whole issue. This leads to
one of two things. The most common symptom of this behavior is memory
"leaks" because the memory simply doesn't get deallocated (nobody ever
bothers deallocating storage). This yields programs which can grow
without bound while they are running. This is not a problem when your
program is a short-lived (small) thing, but if it starts to be part of
a larger program (or server) which is long-lived you can get lots of
wasted memory. The less common (and more difficult to debug) symptom
of ignoring memory management is reclaiming memory too soon. This
means that some part of the program (not the part that reclaimed
too soon) now has a pointer that points to a piece of storage that
is now eligible for reclaimation. This can yield subtle bugs due
to the patterns of reuse in the program. Consider a case where
the reclaimed space is replaced with an object that is similar
(although different) from the original object? This is going to
be hard to track down for the programmer who wrote the code that
uses the pointer after the original object is gone...
Almost any reasonably large software system has some sorts of
"application specific" reclaimation strategy. These vary widely from
custom "reference counting" (see below) to simply policy documents
given to programmers to tell them "the right way to do it." A big
problem with custom solutions is that people tend to make mistakes;
since every one of these custom solutions is coded one-time for a
one-shot application indicates that buggy code is likely. Further,
the application programmer is unlikely to spend significant time
optimizing the storage/reclaimation strategy thus is not likely
to be particularly efficient. (Empirical studies show that garbage
collectors are actually more efficient that experienced
C programmers...)
Two Phase Abstraction
There are two basic phases in the process of garbage collection. These
may not be explicit an a particular algorithm, but they have to
be there in some form:
- Distinguishing the live objects from the garbage in some way, or
garbage detection and
- Reclaiming the garbage objects' storage so that the running
program can use it
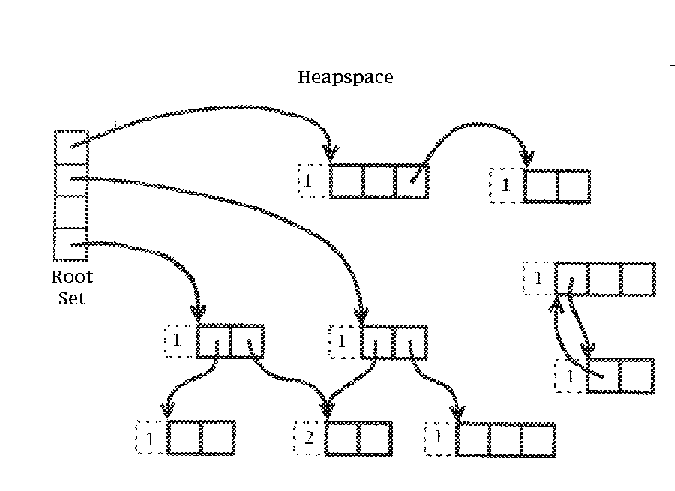
Liveness And The Root Set
There are several criteria that can be used to determine the
"liveness" of data but the one we will use here is the one that is
similar to the one that most collectors use. An object is live is it
is reachable in some series of pointer traversals from the root
set. This root set is the set of all global variables and all
local variables of all active stack frames. Note this inclues
all active stack frames, not just the one executing at the time
of the garbage collection (i.e. all callers of the current function
all the way down the stack).
Let's make sure we understand this for a second. Consider a function
F with a local variable A which calls a function G with
local variables B and C which causes the collector to "come on" and
become active (more on this later). Now, assume that there are also
two globals defined H and I. The root set is the set {A, B, C,
H, I}. Note that a function J which is not currently
executing may have any number of local variables, but these do not
need to be considered. You only need to consider those functions that
are actually executing at the time the collector starts collecting.
Reference Counting
The most basic strategy to employ is reference counting. This strategy
(algorithm) is the most basic and easy to follow. Everytime a new
object is created, a counter is kept (usually with the object) to
indicate how many pointers to the object exist. Initially, this
count is made 1. Everytime a copy of the pointer is made (usually
by assignment) the counter is incremented. When an object holding a
pointer to the reference counted object goes out of scope (goes away)
the reference count is decremented. When the reference count reaches
zero, the object may be reclaimed. Note than when an object is
reclaimed, all pointers it has to other objects also need to
be decremented. Think about getting rid of the "head" pointer in a
large linked list structure.
Advantages of this strategy:
- Incremental Work is done as the program runs, making the
perceived user cost small. It's a "pay as you go" type of strategy
rather than a "collect up all the work and do it at once" type of
strategy.
Disadvantages:
Mark-Sweep
This is the "classical" garbage collection strategy and is named for
the two phases of the GC abstraction we mentioned before:
- Mark This is the process of finding all the garbage. This
is done by tracing: Start at the root set and traverse the graph of
pointer relationships (using either DFS or BFS). The objects found are
marked in some way, this is frequently by setting a bit on
the object itself.
- Sweep This is the process of reclaiming the garbage. Now
that we have a mark that differentiates the live objects from the
garbage, we sweep the memory space (exhaustively search) and
reclaim the garbage. Traditionally (as with reference counting) we
link the now reclaimed objects onto a "free list" which is the list
of available storage locations.
There are three big problems with mark-sweep collectors:
- Fragmentation The heap will get fragmented unless you make
efforts to mitigate this problem. This will eventually lead to a
situation where you have a large amount of free memory but no large
block of free memory, so you will be unable to allocate enough
space to hold a large allocation. (This fragmentation problem is not
limited to mark-sweep collectors, reference counting, and most
explicit heap-management strategies also have this problem.)
- Cost The cost of the mark-sweep approach is proportional
to the size of the heap and independent of the number of live
or dead objects. The entire heap must be checked for garbage on each
collection.
- Locality of reference This problem is that because the
live objects are interspersed throughout the heap, over time objects
of very different ages can end up being neighbors. This means that
various operating system and hardware optimizations based on locality
of reference will be useless.
It is noted by Wilson that sufficiently clever mark-sweep
implementations on real data may be considerably more efficient than
the three problems above would suggest. High-tech mark-sweep
implementations are, in fact, about as fast as copy collectors (see
below).
An optimization on the mark-swep strategy is to use a mark-compact
collector. This collector uses a marking phase like the mark-swep
collector, but then "slides" the live objects "down" in memory until
they are all contiguous. This eliminates the fragmentation problem
above, leaving all the garbage at one end and all the live objects at
the other. Unfortunately, this approach is like mark-sweep in that it
uses multiple passes over the heap to do its work. For more on this,
see Donald Knuth's Art of Computer Programming: Volume 1.
Copying Collectors: Stop and Copy
Like a mark-compact collector, a copying collector does not really
"collect" garbage, but rather moves all the live objects to a
particular area of memory so that the other area is available for use
(and is garbage). The basic scheme here is to use a traversal phase
similar to the mark phase above, but as live objects are found they
are immediately moved to some particular part of memory. This allows
objects to (generally) only be traversed one time. Sometimes this
process is called scavenging.
Semispace Collectors
In this scheme, the heap is divided in two contiguous semispaces.
During normal program execution, only one of these semispaces is in
use. When program demands an allocation that will not fit in the
current space the collector is invoked and it goes through the
following procedure:
- Find all the live data via tracing (as above with marking).
- As you find a live piece of data, copy it from the current
semispace (the "fromspace") to the other semispace (the "tospace").
- The tospace is now made the current semispace and execution
continues. Thus the roles of the two semispaces are reversed on each
collection.
Here is a diagram that may make it easier to understand:
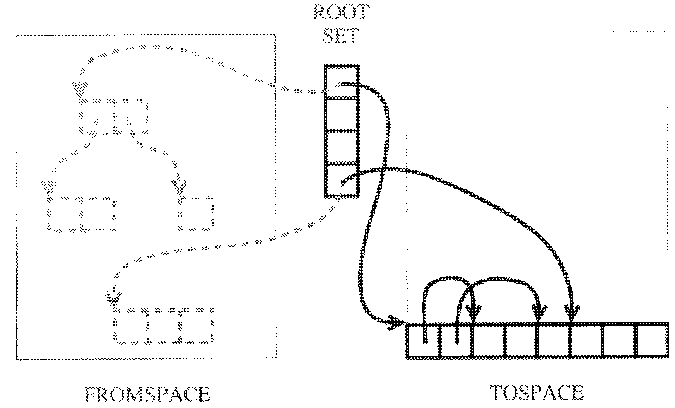
Think about an object that can be reached by multiple paths! One has
to be careful not to end up with multiple copies of it in the
tospace...
There are some very nice properties of copying collectors:
- The amount of work done is proportional to amount of live
objects at the time of the GC. If we assume that approximately the
same amount of objects are live at all points in the program's
execution, we can decrease the amount of work done by simply reducing
the frequency of garbage collections.
- Adding more memory to the semispaces (making the heap larger)
will reduce the frequency of collections. Think about it, if there is
more space in the current semispace, the program will take longer to
fill it! Intuitvely, what we are doing is increasing the average age
of objects which we end up copying when we increase the size of the
heap. Keep in mind that objects which become garbage before
any collection is done never get copied! If we increase the size of
the heap, we are increasing the chances that short-lived objects
never get collected.
Some overall points
- In practice, it is not the asymptotic complexity (the big O) of
the collection algorithm which really matters in terms of
performance. The constants come it to play and will need to be
considered. This is the reason that mark-sweep and copying collectors
(assuming state-of-the-art implementations of each) are competetive in
terms of performance.
- A major win of in-place collectors (such as mark-sweep) is that
they can be used with languages/compilers which do not unambiguously
identify pointers at run time. A copying collector (or compacting
collector) must be able to identify pointers so it can modify them
when the pointed to object is moved by the collectors. In a language
like C (in which pointers and integers are interchangable) think about
the havoc that would be wreaked by a garbage collector which confused
some of the integers in the program for pointers and began modifying
them!
- The lower bound on the work of the copying collector is
excellent (it approaches zero as the amount of memory becomes
very large), but this hard to achieve in practice (as infinite memory is
fairly expensive...). All of the GC schemes so far discussed have
various properties which make them difficult to evaluate simply with
respect to their interaction with the virtual memory systems that are
today in use almost everywhere.
Incremental Tracing Collectors
All the schemes that we have seen so far involve actually
stopping program execution while the collector performs its
duties. This may annoy the human user if the pause in the execution of
the program is large enough to be noticable. What you really want is a
collector whose execution can be interleaved with the execution
of the program. This property is known as the collector being
incremental. In this discussion, there is not much difference
between mark-sweep and copying collectors; further, we will
concentrate on the incremental tracing out of the garbage, not the
incremental reclaming of the garbe as the tracing is far mroe interesting!
The big problem arises if the collector has not
completed its traversal of the graph and the program changes (mutates)
the graph while the traversal is in progress. Needless to say, this
is going to substantially complicate the traversal process. Some
mechanism(s) must be put in place to insure that the collector can
recover from these mutations. Various strategies can be used to deal
with this problem...
We will not go into incremental collectors in any detail in our
discussion here except to say two things:
- Incremental GC is the way to go. Many real-world systems actually
employ incremental techniques to try to improve perceived user
performance.
- A useful mental model of the process of incremental GC might be
to think of a wavefront passing over the heap. The objects which are
completely checked, known to be live, and all their decendents
(pointers from them) have been checked are colored black. Objects
still subject to GC are colored white (might be live or
garbage). Objects colored grey are still in the process of being
checked (they have been checked themselves, but their decendants
haven't). The "wave" is a grey wave over a white heap, and when the
wave passes completely over an area, all remaining objects are
black. The question to be addressed is what happens if during the wave
movement a black object or grey object or white object gets modified
by the program (mutator)?
Generational Collectors
It has been observed by a variety of people who study programming
languages that in almost all languages a very large percentage of the
objects live a very short time while a few objects live
much longer. How can we capitalize on this property? We
can segregate our memory objects by age.
Consider dividing the heap into two areas, the Old geneartion and the
New generation. Each of these areas is further divided into two
semispaces. Objects are always allocated in the New generations
semispaces, and the collector runs over the New semispaces (only) in
the normal manner. Objects which survive some number of passes of the
collector in the New area are moved into the Old area in the current
Old semispace. This space will eventually fill up and also have to
be collected, but significantly less often than the New space. Moving
objects into the Old space removes them from consideration every time
the New space is collected. You also can add more "generations" than
just the two we have here...
Crucial to the success of these schemes is the ability to scavenge the
New generation without scavenging the Old generation. This implies
that one cannot have pointers that point from one generation to
another (consider how the tracing works!) or if such pointers are
allowed that the collector knows about them. If one did not detect (or
disallow) inter-generational references, garbage might be detected
incorrectly, and pointers might not get updated when objects
move.
We won't go into a lot of detail of how this done, but in short it
requires that the system do bookkeeping to know where pointers exist
from older generations to newer ones. These are used as part of the
root set for finding garbage in the newer generation. Note that this
is a "conservative" approximation of garbage: The older object holding
the pointer to the newer generation may be garbage itself, but the
collector doesn't know this yet, it assumes the older object is
live. The upshot is that newer garbage might not be reclaimed as soon
as it could be. Also, note that the much more common case is
pointers from newer data to older data (consider CONS)... this
case is not a problem as when Old memory is scavenged it is done in
conjuction with a scan of New memory.
Back To The CS2360 Home Page
Ian Smith (iansmith@cc.gatech.edu)
Last Modified 27 Feb 95 by Ian Smith (iansmith@cc.gatech.edu)