A Reactive Implementation of the Tau Protocol Composition Mechanism
R. Clayton
K. L. Calvert
Networking and Telecommunications Group, College of ComputingGeorgia Institute of Technology
Atlanta, Georgia 30332-0280
404 894 1155, 404 894 9107
clayton@cc.gatech.edu, calvert@cc.gatech.edu
This work was supported in part by the U.S. National Science Foundation under grant NCR-9612855.
Abstract
Keywords: reactive systems, protocol framework, NETBLT, transport services
1. Introduction
Recent years have seen a flurry of activity in the higher levels of network architecture. Applications are being developed and specified at an unprecedented rate. Many of these applications are adequately served by TCP and UDP, however some are not. In the present Internet architecture, end-to-end services other than reliable byte-stream (TCP) and best-effort datagram (UDP) are often integrated with the application, because there is no general mechanism for composing and re-using individual functions such as congestion control. Applications thus have to either implement these functions themselves, use functions they don't need (i.e. TCP), or forego them altogether.
A related problem is that of flexibility with respect to the services used by a particular application. The canonical example is security: sometimes HTTP needs to be run over a secure encrypted connection, while at other times this overhead is unnecessary. In the Internet protocol architecture, port numbers are the only mechanism available to encode the presence or absence of such services. Thus, Web servers listen on two ports: one for secured connections (using a specific protocol, i.e. SSL), and one for normal connections. The only way for a client to determine that a given server does not support security is to attempt to connect to the corresponding port. In general, this approach causes the number of well-known port numbers to grow exponentially in the number of services (or protocols implementing services) whose presence or absence needs to be encoded.
To summarize: the present Internet Architecture stops at TCP and UDP, relegating all other services and combinations of services to the application. This situation impedes the deployment of new network applications by making it difficult to implement, configure, and use such services unless they are integrated into the application. What is needed is general approach to organizing these kinds of services and enabling them to be composed in various ways. (Note: although the OSI protocol architecture extends beyond the Transport level, various aspects of it - including its insistence that each of seven layers be present - preclude its consideration as a solution.)
Toolkits are one standard technique for dealing with complications of the kind involved with provisioning network services. A toolkit is essentially a codification of a set of solutions for a specific problem. For example, the ISIS toolkit (Birman and van Renesse, 1994) represents a particular set of solutions for providing group management and communication services. Toolkits, being associated with specific problems and solutions, tend to have limited scope. In addition, the preciseness of their assumptions and attendant solutions tend to fragment the system into components that are difficult to re-integrate into a higher-level system. (Here we are talking about horizontal integration, as opposed to vertical integration. Most toolkits are made to be vertically integrated. Horizontal integration is more difficult, principally because of the heterogeneous nature of the components, as can be appreciated by considering how ISIS might be integrated with Kerberos, a toolkit providing authentication services.)
Frameworks are also an attempt to codify solutions, but at a more general level than toolkits. An exact definition of a framework is problematic, but if a toolkit is a software system embodying both mechanism and policy, then a framework is a software system embodying only mechanism. The x-kernel (Hutchinson and Peterson, 1991) is an example of a framework for implementing protocols, as is the Conduit and associated patterns (Zweig and Johnson, 1990).
This paper describes Tau (Transport and up), a proposed solution to the problem described above. Tau has some characteristics of a framework, but also implements some functionality of its own (including addressing). It is more than a toolkit, because it is intended to be fully extensible in certain dimensions. Perhaps it is best described as a platform, one that supports dynamic configuration of efficient end-to-end communication services composed from reusable protocol functions. A primary objective of Tau is to support addition of new functionality after Tau has been implemented and deployed. To that end, Tau features a generic protocol interface (GPI), which defines the shape of all protocol functions. The purpose of the GPI is to hide details of how protocol functions are composed from the protocol implementor, who is then free to focus on how to implement the desired function (Calvert 1993).
Another design goal is for Tau to provide common-path performance comparable to existing protocol implementations, (i.e. TCP and UDP) for comparable services. The design of the GPI is interesting and challenging for several reasons, most especially the tradeoffs among the design goals of flexibility, modularity and performance.
Given a platform that supports dynamic selection and configuration of protocol services, there is still the nontrivial problem of determining which configuration to provide to a particular application instance, and when to change the configuration. Solutions to this problem are outside the scope of Tau, which assumes the existence of a configuration manager that decides which functions to configure for each session (or even each packet), and informs Tau of its decision. The configuration manager might be implemented in the application itself, or it might be a separate function at the same level as Tau. Tau's relationship with this configuration manager as well as its position in the overall architecture is shown in Figure 1.
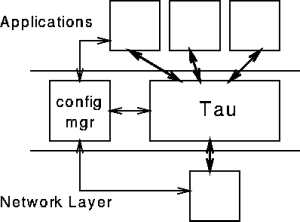
Figure 1. Tau context
The remainder of this paper has two main parts. In the first part we give a general overview of the Tau platform. Then we highlight issues involved with defining a generic protocol interface, consider various models that might be used to reason about and implement such an interface, and argue that the model of reactive systems offers advantages over others. The second part of the paper (Section 3) describes our experience using a reactive approach to protocol composition in implementing a specific protocol (NETBLT) from protocol function components.
2. Tau Overview
The goal of the Tau project is provide an architecture for common end-to-end services (i.e. those services above the network layer that can reasonably be expected to be used by different applications) based on insights gained from protocol design research over the past two decades. The Tau platform has three main components:- a metaheader protocol, which supports once-for-all demultiplexing and describes the processing to be applied to each Tau data unit;
- a generic protocol interface, which enables protocol functions to be plugged into slots in the Tau framework, and frees implementors from worrying about details of the protocol composition mechanism;
- a set of individual protocol functions such as flow control, connection management, encryption, etc.
A common feature of many of these techniques is that they are precluded by the use of layering as a composition mechanism. Although layering makes sense for some interfaces in a protocol architecture (viz., at natural multiplexing and switching points such as the top and bottom of the network service), at other points it hides information that can be useful in planning and carrying out the processing of a protocol message - e.g. the configuration of protocols present in a message. For this reason, Tau does not rely on layering to compose protocol functions; rather, it provides a backplane structure, into which protocol functions can be inserted.
Figure 2 shows the general organization of the Tau framework and the data flow processing of an incoming message. Each protocol function is viewed as a passive transducer, which is given inputs (state information, header from the incoming message, and in some cases user data) and produces outputs (updated state information, control parameters, possibly a reply header, and processed user data). The architectural glue is provided by the demux-and-dispatch function, which is responsible for invoking and coordinating the protocol functions, providing them with inputs (i.e. parsing incoming headers and retrieving relevant state information), and collecting and passing on to the external environment (i.e., the user, the network, and auxiliary functions such as timeout and buffer management) their outputs. Logically, the protocol functions operate independently and concurrently on any given message, except for data-handling functions, which in general have to be executed in some sequential order for correctness (e.g., sender and receiver need to agree on the order in which to perform encryption and checksumming).
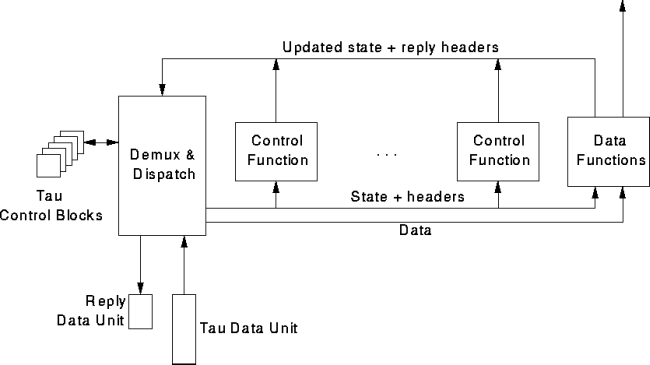
Figure 2. The Tau architecture.
2.1 Related Work
A number of configurable protocol frameworks have been proposed and-or developed, including O'Malley and Peterson's Dynamic Architecture (O'Malley and Peterson, 1992), FCSS (Zitterbart et al., 1993), DaCaPo (Plagemann et al., 1993), HOPS (Haas, 1991), and ADAPTIVE (Schmidt and Suda, 1993). In addition, various researchers have proposed protocols that offer flexible functionality for particular purposes (LaPorta and Schwartz, 1993; Feldmeier, 1993). Tau has in common with these the idea that an application should be able to select from a menu the protocol functions it needs. It differs in being explicitly designed to support almost arbitrary extension of the set of services it can provide, in its avoidance of layering as a composition mechanism, and in its aim of providing a standard platform (which might be realized in many different ways) rather than an environment that must be present on both ends.The work of Bhatti and Schlichting (1995) on creating composite protocols in the x-kernel is probably closest to the philosophy of Tau. Like their approach, Tau features a generic protocol function interface; it differs, however, in emphasizing the development of a platform - a protocol for bits on the wire and in its approach to composition.
2.2 Metaheader Protocol
The metaheader protocol defines the bits on the wire needed for interoperability among Tau implementations. It supports five functions provided by Tau itself:- Application addressing.
- Multiplexing and fast session state retrieval (the session identifier used to locate relevant state for an incoming message is chosen by the message recipient).
- Error detection over Tau protocol control information (i.e. a checksum over everything in the Tau message that precedes user data).
- Reply advice, which tells the receiving Tau whether to send reply messages immediately or wait for an application response.
- Configuration information describing the headers present in the message, and indicating what processing to apply to the message.
Two types of configuration description are supported. The first type is the most general: the Tau metaheader is followed by a list of header descriptors, one for each protocol function that needs to be applied by the recipient to the message. Each header descriptor contains the protocol identifier as well as the size and location of the corresponding protocol header (if any). This information enables the receiving Tau to locate and pull out the actual headers from the message, and determine which protocol functions to invoke. This type of configuration description can support essentially arbitrary combinations of protocol functions.
The second type of configuration description assigns concise identifiers to common protocol header configurations, and omits the header descriptors to reduce overhead. This well-known configuration number can be used to index into a table of parse-and-dispatch routines, each of which pulls out the headers present and invokes the appropriate functions.
2.3 Generic Protocol Interface (GPI)
The objective of the Generic Protocol Interface is to "carefully separate aspects of protocols that are externally visible (i.e. affect headers and data) from those that deal with `infrastructure'" (Calvert, 1993) - in other words, to maximize the separation of functions from the glue that binds them together. In most architectures that feature some form of general protocol interface, the protocol implementations interact directly with each other. To maximize flexibility, these interfaces typically impose few constraints on the way protocols interact with each other. In practice, this leads to hidden assumptions (e.g., about responsibilities for buffer de-allocation) that make it difficult to re-use implementations in different configurations.In Tau, the idea is that protocol functions interact only with the Tau framework, which provides them with all information (i.e. headers and state) needed for processing. The advantages of this approach include:
- Assumptions about protocol functions in the environment are minimized.
- No ordering is imposed on protocol processing, unlike with layering. This removes one obstacle to parallel implementations, although parallelism at this level has not yet been shown to be effective. (Note that ordering can be imposed and declared in the metaheader where it is necessary. For example, the order of application of functions that modify user data must be known at the receiver.)
- Information about common functions can be exploited to provide fast path processing.
For example, a protocol function responsible for sending acknowledgments of incoming data units needs one bit of information from the checksum function, namely whether the data unit was received correctly. This is an example of a more general problem that does not arise with layered composition: some protocol functions are show-stoppers, i.e. they cause processing on a data unit to be aborted or delayed. In a layered architecture, the next protocol in the sequence never sees the data unit. In the logically parallel framework of Tau however, other functions may already have processed the data by the time the show-stopper is discovered. For example, a sequencing function may determine that an incoming data unit is not in the receive window, and therefore should not be delivered to the user. (We consider copy-out to the user's data space a separate protocol function.)
To solve this and other problems, Tau will segregate these show-stopper functions, and invoke them before any other processing. If any show-stopper raises an exception that would cause a message to be aborted, any completed processing must be rolled back, and other functions may not be invoked. (Note that some functions might be invoked even when a received data unit is erroneous. For example, flow control window information for the opposite direction of data travel would be useful even if a checksum indicates the user data is corrupted, as long as the header itself is not corrupted. This is the reason Tau has a separate checksum for header and metaheader information.)
Another problem caused by horizontal composition is more difficult to solve: functions that cause data to come to rest in one way or another inside Tau are not conducive to this form of composition. The canonical example of such a function is fragmentation and reassembly, which clearly cannot be logically independent of functions such as checksumming and sequencing. Tau's solution is simply to proscribe composition of such functions with others in the same layer, and to permit Tau to be used recursively, i.e. layered on top of itself. Obviously there is a performance penalty for this form of composition, but the point is that those applications that really need fragmentation and reassembly can get it.
Conceptually, the Generic Protocol Interface regards an individual protocol
function as a transducer that maps a tuple (state, header, [user
data]) to another tuple (new state, [reply header], [user
data]). Each protocol function provides such a mapping (i.e. a method)
for each type of processing: incoming message, outgoing message, new session,
shutdown, state rollback. Some protocols may have methods for other types of
processing, e.g. timeout. Finally, the Generic Protocol Interface also
requires other information about a protocol function: whether it is a
show-stopper or whether it may raise exceptions of various kinds. In
particular, Tau must treat some types of functions, such as flow control and
session management, as special cases, because they affect the processing of Tau
itself (e.g. Tau must check with flow and congestion control before it begins
invoking functions to construct an outgoing message).
2.4 Implementing Tau
This section discusses implementation, first by pointing out important features of Tau the implementation must provide, then by considering possible software models for the Tau implementation, and finally by showing how the chosen software model was used to implement a prototype Tau composition mechanism.2.4.1 Important Tau Features
Before examining the various software models that are applicable to a Tau implementation, it might be a good idea to review the Tau architecture shown in Figure 2 with an eye toward picking out the essential features that the software model would be required to support.Figure 2 has two prominent features: the set of protocol functions making up a protocol, and their arrangement along bus-like control and data paths. An immediate consequence of these features is the need for a generic interface to mediate the contact between the protocol functions and the buses, insuring that protocol functions can be swapped in and out of a protocol's implementation, perhaps dynamically during execution. If this interface is properly designed, it should also simplify the process of incorporating new functions into the Tau framework as they are developed.
Another consequence of the Tau architecture is determining how control moves among the protocol functions. Although exploiting available parallelism is an important objective, assuming sequential execution still raises the question of determining the order in which control passes among the protocol functions. Some of these issues were noted above (e.g. is decompression done before computing the checksum); another is: How is exceptional control provided, as would be necessary when the checksum computation fails, for example?
Even though Figure 2 presents Tau's control and data-manipulation features, the work described in this paper is focused on Tau's control features. Previous work, oriented around data streams and data stream computations, has dealt with data-manipulation protocols (Clayton and Calvert, 1995). Future work will integrate the mechanisms dealing with Tau's control and data-manipulation features into a single system.
2.4.2 Possible Software Models
The objective in implementing Tau is to realize the architecture in a way that minimizes the cost, both at protocol development and execution time, of using the implementation. An important first step in this design is choosing the proper software model to guide the design and implementation of Tau. This section considers several possible software models and justifies our choice of a reactive software model as the basis for a Tau implementation.Object-oriented models. One cannot go too far in the process of designing software these days without having one's attention drawn to object-oriented models (Bapat, 1994). At first glance, it seems that object-oriented models are ideal for Tau; for example, one way to insure interoperability of protocol functions is to have them inherit from the same abstract class. However, our experiences using the object-oriented model to implement protocols, along with taking a second, closer glance, indicates that perhaps object-oriented models were not the anodyne they initially seemed to be.
It is true that interoperability can be insured by having all protocol functions inherit from the same abstract class. However, such interoperability is syntactic, obtained by forcing all protocol functions to presenting the same interface. It is not clear to us, however, that the protocol function for establishing a connection via a three-way handshake should have the same interface as a protocol function providing DES encryption.
Our experiences with the x-kernel (Hutchinson and Peterson, 1991) - which is not, strictly speaking, an object-oriented system, but which is close enough in intent for our purposes - bear out our concerns. During our attempt at implementing the AppleTalk protocol family, we found that the x-kernel's uniform protocol interface, analogous to an interface inherited from an abstract class, occasionally came up short with respect to the control and data that needed to be passed between protocol components, requiring us to distort the implicit semantics of the uniform protocol interface, or subvert it entirely through back doors. If this sort of thing happens when implementing a family of related protocols, it is not to hard to imagine how much worse it could get when implementing a set of largely unrelated and arbitrary protocols.
But even if the technical difficulties of syntactic conformance and the like could be solved, there are larger issues at work too. Tau's control-flow model appears to be considerably looser than that found in most object-oriented models, although we must admit that we find murky the issues around parallel control flow in object-oriented models. Control in Tau cuts across protocol functions, independently of what those protocol functions might be; this is the principle reason for calling Tau's architecture "bus-like".
Such cross-cutting behavior causes difficulties in an object-oriented approach because it doesn't provide much structuring help during object-oriented design, and it doesn't respect any object design that eventually evolve (Kiczales et al., 1997). Such problems were recognized early on in object-oriented design, and dealt with using such paradigms as Model-View-Control in Smalltalk and, more recently, various types of design patterns (Vlissides et al., 1996). However, along with this extra machinery comes a performance hit, a problem which is also being worked on (Schmidt et al., 1995).
It should be noted that we are not saying that object-oriented models cannot be used to implement system software or protocols; we are just saying that, for Tau, object-oriented models are perhaps not the best choice. Note also that we are not denying the usefulness of object-oriented techniques; in fact, a previous incarnation of Tau was implemented in the object-oriented style, and future ones may be also.
Functional models. Functional languages have many desirable properties (Hughes, 1989), and modern functional-programming environments provide powerful facilities for structuring software systems (Tofte et al., 1996). The objective of using functional programming to implement systems software has been a long standing one, with perhaps the must fully realized instance of that objective being The Fox Project (Cooper et al., 1991). Although we also consider functional programming an attractive way to design and implement network protocols, we do not have the resources to devote to establishing an effective functional infrastructure.
Event-driven models. Event-driven models have had a long history of structuring real-time systems, operating systems, and, more recently, graphical user interfaces; event-driven systems have also been applied to structuring protocols (Bhatti and Schlicting, 1995). Figure 2 suggest Tau would also be a good candidate to be implemented as an event-driven system.
There are, however, a few sticking points about event-driven models. First, the event-based communication is usually asymmetric. In particular, events move from the environment to the program, but rarely in the other direction. For example, in the X Windows System events are restricted to traveling from the run-time system to the application; communication in the other direction is done by library calls in the X Window System.
Second, this communication asymmetry may extend into the program itself. If two parts of a program would like to communicate, they generally can't use events to do so, they must rely on some other mechanism. This introduces a dichotomy in the available communications mechanisms, a worrisome prospect for a system like Tau because of the independence with which protocol functions are created and used.
To be most useful as a software model for implementing Tau, event-driven systems should be extended to cover these two short comings: event communication between the computation and the environment should be symmetric, and events should be available for intra-computation communication. Bhatti and Schlicting (1995) provide the second extension but not the first (largely because their system operates within the x-kernel, which does not use events internally).
Reactive models. The closest execution model to event-driven systems are reactive systems (Montague and McDowell, 1997). A reactive system is one that carries an on-going dialog with the environment in which it is executing. An operating system is the prototypical reactive system, as is a real-time control program if you ignore the timing issues. In addition to reacting with its environment, a reactive system tends to be long-lived with no clear stopping point (apart from an explicit stopping signal from its environment).
Despite their similarities, reactive models extend event-driven systems in several significant ways. First, events in reactive systems are fully symmetric; they can travel from the environment to the reactive system and vice versa. In addition, events can be used between components of the same reactive program. The reactive model provides a single, universal, and quite powerful communication mechanism, while event-driven systems must rely on two or more asymmetric communications mechanisms.
A second significant extension made to the event-driven model by reactive systems is the altered interpretations placed on events by reactive systems. Event-driven systems treat events both more generally and more specifically than do reactive systems. Generality shows up in the asynchrony with which events can arrive and influence an event-driven system. Because of such generality, event-driven systems have to be written to handle arbitrary events that may arrive at arbitrary times. Specificity shows up in the priorities and deadlines associated with events in an event-driven system. Because of such specificity, event-driven systems have to be written to order their computations to minimize conflicts between the priorities and deadlines of the associated events; for example it may be that the next event impinging on an event-driven system requires that the system handle the event within 10 microseconds of receiving the event, and do so in preference to any other computations it may be carrying out at the time the event arrives. It is dealing asynchronously with priorities and deadlines that contributes the bulk of the difficulty when designing and implementing event-driven systems. (Note that this paragraph applies more to hard event-driven systems such as real-time control systems; to the extent that an event-driven system can take a more relaxed approach to asynchrony, priority, and deadlines - as is done by GUIs, for example - it begins to resemble a reactive system).
Reactive systems generalize the specific event interpretations of event-driven systems by eliminating or limiting event priority and deadline. This generalization reduces the number of event types and the urgency with which they must be dealt. Reactive systems make more specific the general asynchronous event arrivals through the synchrony hypothesis: all output events occur synchronously with the associated input events, and input events don't interfere with each other; alternative statements of the synchrony hypothesis are "computations triggered by events take no time" and "computations are atomic with respect to events" (Benveniste and Berry, 1991). The synchrony hypothesis greatly tames the difficulty associated with handling asynchronous events; although what event may show up next is unknown, when it will show up can be determined and planned for.
A third extension made to the event-driven model by reactive systems - less significant then the other two because it is fairly easy to see how it can be added to the event-driven model - is the use of co-routines as control construct (here we are referring more to the imperative reactive models used in such languages as Reactive C and Signal).
A reactive construct, once it begins execution, may stop in one of two ways: it can terminate or it can suspend; the choice between the two depends on the code appearing in the construct. When a reactive construct terminates, control leaves the construct and passes on to the next construct (reactive or otherwise) to continue execution.
When a reactive component suspends, control leaves the construct, but can, at some later time, re-enter the construct at the point of suspension and continue execution within the construct. Suspension and resumption may occur repeatedly until the construct terminates. A reactive component, once terminated, cannot be resumed, but it may be reset, which puts the component in the state it had before it was ever executed. When executing a resumed component, control always begins at the component's start; in contrast, when executing a suspended construct, control begins from the point of last suspension, which may be from anywhere within the construct.
This facility provides coroutine-like behavior ("coroutine-like" because suspension doesn't direct control to any particular place, but just causes it to leave the current construct), which is convenient for computations that need to stop and wait because it eliminates the need to save volatile local state in more stable, longer lived storage. A similar facility can be provided by having a dedicated thread execute within a procedure, as can be done in the x-kernel, but reactive suspension is neater because it eliminates the need for thread synchronization using, for example, semaphores.
The execution of a set of reactive components is organized into a sequence of non-overlapping intervals. During each interval, all non-terminated components are given a chance to execute, either by having control enter them in normal sequential fashion or by being resumed. The interval ends when all components stop, either by terminating or suspending; at that point the interval ends (thus, if a component fails to terminate during an interval, the interval never ends).
It is at the start of an interval that the environment interacts with a reactive system. The start of the next interval is marked by the occurrence of a signal from the environment; non-terminated components may ignore or react to the signal as directed by the code they contain.
During execution, a component may issue its own signals; these signals are available to both the environment and the other reactive components. The semantics of synchronous reactive systems require that any signals issued by reactive components during an interval must appear as if they were issued at the start of the interval; it is the job of the run-time system, along with the semantics of the reactive programming language, to insure this illusion obtains.
2.4.3 Implementing Tau as a Reactive System
The description of the protocol composition mechanism given in this section is broken into two parts. The first part presents the high-level, system-oriented implementation details, and the second part presents the lower-level, programmer-oriented details.Figure 3 shows the general outline of the implementation. Signals from the environment, along with any associated data, are captured by the Interrupt Handler, which hangs the signals on the Interval Queue (an interval is reactive-system jargon for the period of computation beginning with a signal and lasting as long as computations are executing in response to the signal). The Scheduler dequeues signals and pairs them with protocol functions waiting for the signals. For each pair found, the Scheduler starts executing the protocol function, passing the signal data, if any. Pairing continues until all waiting protocol functions have been examined, at which point the current interval ends and the Scheduler goes back to the Interval Queue for the next signal.
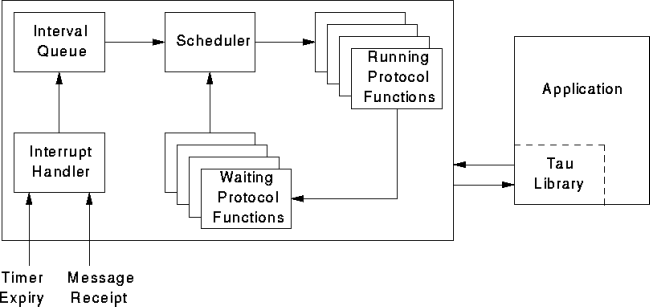
Figure 3. Structure of the protocol composition mechanism.
The Interrupt Handler is configured to recognize packets arriving from the network and host-system timer expiry as signals. In the case of packets, the associated data contains a pointer to the packet itself; timer signals have no associated data. Adding new signals is a matter of reconfiguring the Interrupt handler to recognize the signals in the form provided by the host system. The implementation does not currently allow protocol-function defined signals, but it is clear from Figure 3 how they would be added: a protocol function would hang a signal identifier and associated data on the Interval Queue.
The set of waiting protocol functions can be manipulated by protocol functions, which can add and remove members from the set.
One point not made clear by Figure 3 is the implementation's location within the host system. Currently, it resides in application space, and, in fact, is contained entirely in the Tau library; an application using Tau shares its process space with the Tau implementation. This arrangement is not ideal because Tau uses resources - interrupt handlers, for example - that may be needed by the application, but it is simpler and more convenient to deal with than the alternatives, such as a separate application- or kernel-space implementation.
With the high-level boxes and arrows of the implementation laid out, we can now go into some of those boxes to examine lower-level details.
The C typedef for the generic protocol interface is:
typedef void gpi(void * evnt, void * args);
evnt is an input parameter pointing to a data structure giving
more information about the event that triggered the protocol function's
execution. In the case of messages, evnt points to the message,
its length, and the address of the message sender; evnt is zero
for timer expires because there is no extra information.
The input parameter args is a pointer uninterpreted by
the composition framework; its
interpretation and use is under control of the protocol functions. Generally,
a parent protocol function uses the area pointed to by args to
pass initial values to a child protocol function; a child protocol function
uses the area to store values across invocations.
This version of the generic protocol interface is indeed generic, but
a bit too simple. For example, the absence of any meaningful
semantics for args makes it difficult to determine when
its being misused, either intentionally or unintentionally; in
addition, it is difficult to determine a protocol function's operation
from the information presented by its generic protocol interface.
These difficulties are serious, but are acceptable at this stage of
development because we are interested in developing a prototype to
determine reactive systems' overall fitness for implementing Tau.
Any C function using gpi as its prototype can serve as a protocol
function. Protocol functions are manipulated by the following routines:
mhandler_id schedule_mhandler(unsigned short msg_list, gpi pf, void * args) void cancel_mhandler(mhandler_id)
schedule_mhandler() hangs the protocol function pf on
the wait queue; pf will be removed from the wait queue and set to
running when the scheduler encounters a message of the type indicated by the
bit vector msg_list. schedule_mhandler() returns an
identifier that can be used in cancel_mhandler() to remove the
protocol function from the wait queue; once a protocol function is running,
calling cancel_mhandler() has no effect. A similar set of
routines exists for timer events.
As an example of how these routines are used, the following code periodically sends a message a fixed number of times:
static void send_open(void * iap, void * ap) {
sconnect_argsp scap = (sconnect_argsp) ap;
if (scap->retries_left == 0) {
scap->done = true;
return;
}
send_pkt(scap->nbid, scap->r_host, scap->r_port,
(u1b *) scap->omp, msg_length(scap->omp));
scap->retries_left--;
scap->tid = schedule_timer(scap->response_timeout*1000, send_open, ap);
}
Because send_open() is triggered timer events, the event pointer
iap is zero. The argument pointer ap points to a data
structure containing the retransmission count, the timer interval length, and
information about the message to send. If there are retransmissions left,
send_open() retransmits the message and reschedules itself for the
next retransmission. send_open() continues to execute until it
runs out of retransmission attempts, at which point it indicates it is done, or
it is canceled by some other procedure calling
cancel_timer(scap->tid).
The implementation is roughly 2 000 lines of ANSI C running under Solaris
5.5.1, SunOS 4.1.3, and Linux; code can be found at http://www.cc.gatech.edu/computing/Telecomm/playground/dsa/nbc.html,
where it is coupled with the code for the NETBLT implementation described in
the next section.
3. An Example Tau Protocol
To illustrate the points made in the previous sections, we describe an implementation of the NETBLT protocol within the reactive Tau framework. The NETBLT protocol provides a connection-oriented, bulk-data transfer service optimized for high bandwidth-delay environments (Clark et al., 1987). The two principal features of NETBLT are large buffer sizes and rate-based flow control. Large buffers exploit large memory systems and have the advantage of amortizing transmission overhead over larger transfer units. Rate-based flow control exploits the loose coupling between the peers in bulk-data transfer and has the advantage of lower overhead than found in other forms of flow control, such as sliding windows.There are a number of other NETBLT features of interest, particularly to implementors. Briefly, each buffer is fragmented into packets and sent at the expected rate. At the end of a buffer transmission, the receiver sends a request to retransmit any lost or corrupted packets. To further reduce the transmission overhead, several buffers may be in transit at the same time. NETBLT makes heavy use of timers to detect lost packets, lost peers, and other error conditions. NETBLT has a number of parameters - such as buffer size, packets size, packet transmission rate, and so on - the values of which are under application control and negotiated between the ends of a connection; the burst rate may is also re-negotiated after each buffer transmission.
The overall NETBLT implementation is factored into four parts:
- Endpoint management - creating and deleting NETBLT endpoints.
- Connection management - establishing and tearing down connections.
- Buffer transfer - sending and receiving data.
- Housekeeping - packet send and receive, timer management, and so on.
create() and delete()
from the endpoint-management code, open() and close()
from the connection-management code, and send() and
receive() from the buffer-transfer code; the housekeeping code
exports interfaces used only from within the NETBLT implementation.
Housekeeping involves all the low-level support required by NETBLT: message send and receive, including header completion and checksum computation and validation, intra-NETBLT storage management, and the like. The bus-like aspects of the Tau architecture, along with their realization in a reactive system, served us well here, allowing us to construct protocol functions for these basic activities without particular regard to how and by whom they would eventually be used.
As the system grew, however, we found the number of these basic protocol functions began to get out of hand; determining what function was performed where and how became difficult. In response, we began to combine protocol functions into larger, more specific but still logically cohesive functions; this is why header completion is combined with message sending, for example.
To a certain extent, these problems were brought about by Tau's architecture, with its single, non-hierarchical bus, and its implementation with global, non-scoped events. However, for the most part, this problem is an instance of the common problem of indexing and discovery in system promoting reuse, the general solutions for which involve aspects outside the scope of this paper.
It is in the buffer transfer part that the value of a reactive implementation is clearest. To review briefly: client-to-client data transfer is done in terms of buffers, the size of which is negotiated between the clients. Within NETBLT, each buffer is transferred in packets, the size of which is also negotiated by the clients. Packets are sent at a rate negotiated by the clients; lost and corrupted packet recovery is done by selective retransmission triggered by a timeout after the expected buffer transfer time. To further amortize transmission costs, clients may have several buffers in transit at the same time; the number of buffers in transit is negotiated between the clients.
The open communication patterns provided by events in reactive systems are invaluable in untangling the complex interactions among buffer, packets, and timers in NETBLT. Timer-based code can snoop on message events, setting and resetting themselves according to their purpose, without direct intervention from other parts of the protocol.
The reactive style was a great help in implementing multi-buffer buffer transfers. (The NETBLT Request for Comments (Clark et al., 1987) seems to be contradictory on the subject of packet order during multi-buffer transfers, so what follows is based on our interpretation of what the RFC says, which may not be what it actually says). In multi-buffer transfers, each buffer is sent sequentially, one immediately after the other. In addition to cutting the overhead for inter-buffer coordination between the peers, this allows packet retransmission for previous buffers to be overlapped with packet transmission of the current buffer, which helps keep the pipeline between peers filled.
Replicating the buffer-send protocol function isn't enough to implement multi-buffer transfers because of the need to coordinate packet transmission between the protocol functions, and the need for each protocol function to handle its own packet retransmission.
Connection management too benefits from a reactive style of implementation, although not as dramatically as does buffer management, largely because connection management isn't part of the more complex, commonly executed path through NETBLT. Never the less, the ability to tease out the components of connection management and assign them to separate protocol functions helps simplify and clarify the issues surrounding connection management. For example, the receiving end of a connection, assuming its implemented as a server, executes a cycle of accepting a single connection request and then rejecting all following connection requests until the accepted connection terminates.
A non-reactive language like C makes it easy to implement such functional separations too. For example, a procedure pointer variable could point alternately to a procedure that accepts connection requests and a procedure that rejects them. The questions then become, however, what entity is responsible for flipping the values of the procedure pointer variable?, and what entity is responsible for calling the procedure pointed to?
The reactive implementation of NETBLT answers these questions quite nicely: each protocol function is made responsible for determining how it reacts to a connection request. The protocol functions do this by snooping on events to determine the state of the transfer. If a transfer is in progress, the accept protocol function is inactive and the reject protocol function is active; if there's no transfer in progress, their roles are reversed. This solution, based on local inference and unobtrusive snooping, is much more difficult to provide for in a language such as C.
The endpoint management part of the NETBLT implementation is the least interesting with respect to a reactive implementation. Endpoint management is responsible for creating and managing local instances of a NETBLT endpoint. Because these endpoints are local, the management code has little need to call on the reactively implemented resources - which are largely concerned with providing peer-to-peer services - available deeper in the NETBLT implementation. Instead, endpoint management deals mostly with NETBLT clients and the host system, which are assumed (but not required) to be implemented in a conventional, non-reactive programming language.
This description of the NETBLT implementation has necessarily been sketchy;
those interested in the complete details should consult the NETBLT code at http://www.cc.gatech.edu/computing/Telecomm/playground/dsa/nbc.html,
where the reactive implementation of Tau can also be found.
4. Discussion
To provide some indication of the cost of implementing protocols using this composition mechanism, we now compare two simple echo servers, one implemented in UDP only and the other implemented in Tau over UDP.The UDP-only implementation is the simplest possible. The server waits on a socket read; any datagram read gets immediately echoed back to the sender and the server loops to the read wait again. The client is essentially the same, with the reads and writes reversed, and all within a for loop which iterates n times.
The Tau implementation is as simple as the UDP-only implementation, but with reactive control. The server uses a echo protocol function that reacts to an incoming message, echoing it back to the sender. The client implementation uses the server's echo protocol function to continue the interaction after the first send; after the nth send, the echo protocol function is replaced by a receiver protocol function to read the last echo.
The number of interest is the amount of time it takes the client to echo a k-byte buffer using the echo server. This number is derived by averaging the measurements made by echoing the buffer n times. The client and server were running on the same UltraSparc 1 under Solaris 5.5.1; messages were sent through loop-back.
Table 1 shows the numbers collected with a 1400-byte buffer averaged over 10 000 runs. Not surprisingly, using Tau is twice as expensive as not using it. We are not overly concerned about these numbers because, at this early stage of our work, our interests are focused on other, more immediate issues such as suitable architectural features for Tau and effective implementation strategies. When we have advanced enough in our work we can turn our attention to performance issues. Nor are we able to discern from these numbers an omen that we've chosen a disastrously wrong path to implementing Tau. We have just included these numbers as a convenience to those who must see performance numbers when reading about protocols.
| UDP client | Tau client | |
| UDP server | 280 | 420 |
| Tau server | 450 | 570 |
Table 1. Performance overhead imposed by the reactive composition mechanism (units are microseconds).
Of more importance to us at the moment is the conceptual efficiency afforded by the Tau architecture when designing and implementing protocols. Although conceptual efficiency is harder to qualify and quantify than is execution efficiency, our experiences up to this point with the current implementation have been positive.
A previous realization of the same service was based on an explicit process and pipe composition mechanism; each protocol function is a thread, and protocol functions communicate by sending messages along uni-directional pipes. Using processes and pipes to design protocols was reasonably simple, but using them to implement protocols was considerably more difficult.
A majority of the difficulties arose from the unconstrained asynchrony implicit in having ten to fifteen threads executing per NETBLT endpoint. With so much asynchronous activity, it becomes difficult to determine the overall state of the system at any particular time during execution. Normally, it shouldn't be necessary to determine overall state, but when the system isn't working, or isn't working as well as expected, it becomes important. As another example, one related to the normal execution of the system, terminating threads in an ordinary fashion turned out to be amazingly difficult. Globally killing them outright is one possibility, but it makes orderly resource recovery difficult.
In contrast, the reactive implementation also provides threads, but in a form more constrained then that described in the previous paragraphs. In particular, parallelism triggered by events combines the advantages of concurrent execution with global control, making it easier to test assertions about the state of the system.
4.1 Further Work
The next-generation system we are designing and building is based on a version of the synchronous programming language SL (Boussinot and de Simone, 1995). With respect to Tau, the most interesting feature of S, the language serving as the basis of the next-generation system, is the use of signals to implement the Generic Protocol Interface.In S, as in SL, protocol developers may declare their own signals, as in
proc send_msg(msg : vector unsigned byte, msg_size : unsigned int)
signal ready(unsigned int, vector unsigned byte)
// and so on...
In this example, ready is a signal with two parameters, the first
accepting an unsigned integer and the second accepting a reference to a vector
of unsigned bytes. These parameters are used to transfer values from the
entity that raised the signal to the entities waiting for the signal.
The other interesting trait of S signals, which is also true of signals in SL,
is that they are scoped with respect to the lexical constructs in which they
are defined; in this respect signal declarations behave as do variable
declarations in block-structured languages. In the previous example, lexical
scoping means the ready signal is available only within the send_msg procedure.
When raised, the ready signal only propagates within the body of the send_msg
procedure; entities outside send_msg cannot react to
ready.
In addition to developing and refining the reactive control semantics in the next-generation system, we plan to determine how to best introduce into the system our data-stream subsystem. The combination of both control and data functions will give us a complete, reactive implementation of the Tau architecture.
5. Conclusion
The demand for upper-level network services has spurred research into techniques supporting the design and implementation of protocols at the transport layer and up. Tau is being developed to integrate these various techniques into a flexible and efficient framework for protocol development.Reactive software offers an attractive model for implementing the Tau framework. In addition to providing an execution environment close to that found in most protocol subsystems, reactive software offers a number of desirable properties not found in closely related software models, such as event-driven systems; these properties include full symmetry in communication among components, better integration with other software components, and a firmer theoretical model.
This paper has described an initial reactive implementation of the Tau framework, and shown how it can be used to implement the NETBLT bulk-transfer protocol. Preliminary implementation experiences indicate that the reactive model can be an effective and convenient way of implementing protocol software, although some performance cost is involved.
Bibliography
Bapat, S. (1994) Object-Oriented Networks: Models for Architecture, Operations, and Management. Prentis-Hall, Englewood Cliffs, New Jersey.
Benveniste, A. and Berry, G. (1991) The Synchronous Approach to Reactive and Real-Time Systems. Proceedings of the IEEE, 79(9), 1270-1282.
Bhatti, N. and Schlicting, R. (1995) A System for Constructing Configurable High-Level Protocols. Computer Communications Review (SIGCOMM '95 Proceedings), 25(4), 138-150.
Birman, K. and van Renesse, R. (1993) Reliable Distributed Computing with the Isis Toolkit, IEEE Computer Society Press, Los Alamitos, California.
Boussinot, F. and de Simone, R. (1995) The SL Synchronous Language, INRIA Research Report 2510, Sophia-Antipolis, France.
Calvert, K. (1993) Beyond Layering: Modularity Considerations for Protocol Architectures, in Proceedings of the IEEE International Conference on Network Protocols, October, San Francisco, USA.
Clark, D., Lambert, M., and Zhang, L. (1987) NETBLT: a bulk data transfer protocol. Request for Comments 998, Network Working Group, Internet Engineering Task Force.
Clark, D. and Tennenhouse, D. (1990) Architectural Considerations for a New Generation of Protocols, in Proceedings of ACM SIGCOMM 90, September, Philadelphia, Pennsylvania, 200-208.
Clayton, R. and Calvert, K. (1995) Structuring Protocols with Data Streams, in Proceedings of the Second International Workshop on High Performance Protocol Architectures, December, Sydney, Australia.
Cooper, E., Harper, R. and Lee, P. (1991) The Fox Project: Advanced Development of Systems Software, School of Computer Science Technical Report CMU-CS-91-178, Carnegie-Mellon University, Pittsburgh, Pennsylvania, August.
Feldmeier, D. (1990) Multiplexing Issues in Communication System Design, in Proceedings of ACM SIGCOMM 90, September, Philadelphia, Pennsylvania, 209-219.
Feldmeier, D. (1993) An Overview of the tp++ Transport Protocol
Project, in High Performance Networks - Frontiers and Experience, Kluwer
Academic Publishers, Boston, 157-176.
Floyd, S., Jacobson, V., and McCanne, S. (1995) A Reliable Multicast Framework for Light-Weight Sessions and Application Level Framing, in Proceedings of ACM SIGCOMM 95, October, Cambridge, Massachusetts, 342-356.
Haas, Z. (1991) A Protocol Structure for High-Speed Communication over Broadband ISDN, IEEE Network 5(1), 64-70.
Hughes, J. (1989) Why Functional Programming Matters. The Computer Journal, 32(2).
Hutchinson, N. and Peterson, L. (1991) The x-Kernel: An Architecture for Implementing Network Protocols. Transactions on Software Engineering, 17(1), 64-75.
Kiczales, G., Lamping, J., Mendhekar, A., Maeda, C., Lopes, C., Loingtier, J.-M., and Irwin, J. (1997) Aspect-Oriented Programming, Xerox PARC Technical Report SPL97-008 P9710042, Palo Alto, California, February.
LaPorta, T. and Schwartz, M. (1993) The MultiStream Protocol: A Highly Flexible High-Speed Transport Protocol, IEEE Journal on Selected Areas in Communications, 11(4), 519-530.
Montague, B. and McDowell, C. (1997) Synchronous/Reactive Programming of Concurrent System Software. Software Practice and Experience, 27(3), 207-243.
O'Malley, S. and Peterson, L. (1992) A Dynamic Network Architecture. ACM Transactions on Computer Systems, 10(2), 110-143.
Plagemann, T., Plattner, B., Vogt, M., and Walter, T. (1993) Modules as Building Blocks for Protocol Configuration, in Proceedings of the International Conference on Network Protocols, October, San Francisco, 106-113.
Schmidt, D., Harrison, T., and Al-Shaer, E. (1995) Object-Oriented Programming for High-Speed Network Programming in Proceedings of the USENIX Conference on Object-Oriented Technologies, June, Monterey, California.
Schmidt, D., and Suda, T. (1993) Transport System Architecture Services for High-Performance Communications Systems, IEEE Journal on Selected Areas in Communications 11(4), 489-506.
Tennenhouse, D. (1989) Layered Multiplexing Considered Harmful, in Proceedings of the IFIP Workshop on Protocols for High-Speed Networks, May, 143-148.
Tofte, M., Launchbury, J., Meijer, E., and Sheard, T. (1996) Essentials of Standard ML Modules, in Tutorial Text to the Second International School in Advanced Functional Programming, August, Olympia, Washington, 208-238.
Vlissides, J., Coplien, J., and Kerth, N. (1996) Pattern Languages of Program Design 2. Addison-Wesley: Reading Mass.
Zitterbart, M., Stiller, B. and Tantawy, A. (1993) A Model for Flexible High-Performance Communication Subsystems, IEEE Journal on Selected Areas in Communications 11(4), 507-518.
Zweig, J. and Johnson, R. (1990) The Conduit: A communication abstraction in C++, in Proceedings of the USENIX C++ Conference, April, San Francisco, California, 191-204.
R. Clayton is a Ph.D student in the Networking and Telecommunications group in the College of Computing at Georgia Tech.
Kenneth L. Calvert is an Assistant Professor in the College of Computing at the Georgia Institute of Technology. He received the Ph.D. degree in 1991 from the University of Texas at Austin. From 1979 to 1984 he was a Member of Technical Staff at Bell Telephone Laboratories in Holmdel, New Jersey. Dr. Calvert's current research interests include active networks, development of an end-to-end protocol framework for the Internet, information infrastructure (middleware) for the home environment, and topological models of the Internet.