HIPED
Heterogeneous Intelligent Processing for Engineering Design
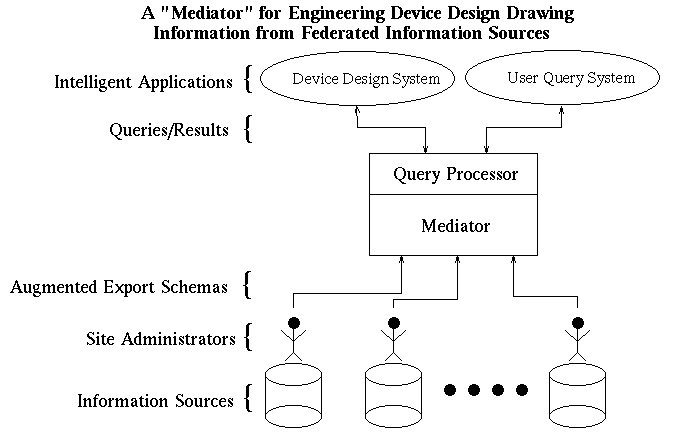
Future progress in intelligent systems (e.g. engineering design, planning, etc) requires improvement in Knowledge Base / Data Base (KB/DB) access. We believe two of the most important issues with respect to KB/DB access are scalability (how much information is available to the intelligent system) and usability (how easily can the intelligent system access ALL the relevant information). To explore usability in interfacing intelligent systems to large-scale information sources, we have experimented with providing knowledge from an external information to an interactive knowledge based design environment known as Interactive Kritik by using IDI as the interface to an Oracle database.Two approaches to scalability of available knowledge are construction of a large, monolithic system containing all the information and integrating access to a distributed set of information sources. We choose the latter because it lends itself to truly large-scale integration of information and it more easily facilitates incremental (collecting the knowledge over time rather that all at once) integration of information. To this end, we have developed an integration paradigm which allows the administrator of an information source to describe their data in the form of an Augmented Export Schema (AES). The AES can then be used to expand the current global schema so that the new information is accessible. We have developed a package called JOIN which takes an AES and the current global schema and derives a new global schema representing all the information available to global users.
Current Research
We are trying to address various aspects of query processing in distributed heterogeneous environments with special emphasis on incorporating knowledge at different levels. The knowledge relates to information about the sources of data, their structure, their content, and their overall relevance to the problem at hand.Our present approach to the issue of incorporating knowledge into query processing and formulation can be broken down in three areas:
- Query Formulation
- Semantic and multiple Query Optimization
- Incorporation of learning into the mediation task
Query Formulation
In the query formulation area, we are investigating issues involved in integrating multiple sources of semi-structured data like text documents. We are studying user interface and visualization techniques to let the user discover the ways in which data is organized. This allows the user to determine how meaningful the underlying information sources are. and to discover the potentially useful ones. Some of the methods being used are:
- Use of thesaurus during the query formulation process to prompt the user with additional words related to the query.
- Techniques to visualize the query results and compare them with query words.
- Feedback from the user at different levels of granularity (like clusters of documents, individual documents, parts of a document, phrases and words.
Semantic and Multiple Query Optimization
Query optimization is a decision process that selects the best query evaluation strategy from a set of execution plans. The performance of this process can be improved by providing better information about the contents of the database (i.e., meta-data). Furthermore, the process itself can be improved by incorporating the semantics of the database and by considering global plans which optimize execution over a set of queries.A Meta-Data View Graph (MVG) is a network for organizing and managing information about a database. The nodes of the network represent logical views of the database and contain information specific to the corresponding data set. Statistical information (e.g., selectivity factors) is used by the query optimizer to generate more accurate estimates of execution cost. Semantic information (e.g., integrity constraints) is used to transform a query into a set of semantically equivalent queries giving the selection process more plans to choose from. Finally, when given a set of queries, the MVG network can identify common subexpressions, the results of which can be computed once and shared among the set of queries.
Incorporation of learning into heterogeneous database mediation
Large-scale integrated knowledge systems can be, and often are, opaque to their users. But if the knowledge organization and information processing in these systems is not transparent, then the user may not be comfortable in using the system or be confident of the results it produces. Three issues are considered in designing transparent knowledge systems: how to explain and illustrate the system's reasoning to a user, how to explain and justify its results, and how to enable the user to explore and navigate its knowledge base.In particular, endowing the knowledge systems with explicit models of their own reasoning process may provide useful answers to these questions. The Interactive Kritik system is developed from earlier systems in the Kritik series of autonomous device design programs. It presents to the user a model of its reasoning based on a hierarchy of tasks and methods which refer to as a Task-Method-Knowledge (TMK) model.
The plan is to use the above systems together with real large scale databases to enable designers to access information of a heterogeneous nature intelligently for solving their design problems.
We need to expand our current set of integration tools to accomplish large- scale integration. Future work includes:
- Construction of Augmented Export Schema development tools to allow information source administrators to completely/accurately represent their data.
- Extend the reasoning capabilities of JOIN by allowing more types of inferencing on schema correspondences and consideration of user feedback.
- Development of query processing facilities which support users searching a very large information space. Such facilities include explanation of query results, suggestion of future query directions, and visualization of information relevancy.
Publications:
- A Goel, S Bhatta, E Stroulia. Kritik: An Early Case-Based Design System. To appear as a chapter in Issues in Case-Based Design, Maher and Pu (editors), MIT Press 1996.
- A Goel, A Gomez, N Grue, J W Murdock, M Recker, and T Govindaraj. Explanatory Interface in Interactive Design Environments. To appear in the proceedings of the 1996 AI and Design conference.
- A Goel, A Gomez, N Grue, J W Murdock, M Recker, and T Govindaraj. Towards Design Learning Environments - I: Exploring How Devices Work. To appear in the proceedings of the 1996 Intelligent Tutoring Systems conference.
- S Navathe and M J Donahoo. Towards Intelligent Integration of Heterogeneous Information Sources. In Proceedings of the 6th International Workshop on Database Re-engineering and Interoperability, March 1995.
- J Pittges. Maintaining Instance-Based Constraints for Semantic Query Optimization. Proceedings of the Sixth IFIP TC-2 Working Conference on Data Semantics (DS-6), Stone Mountain, Georgia, May 1995